在无限的平面上,机器人最初位于 (0, 0) 处,面朝北方。机器人可以接受下列三条指令之一:
"G":直走 1 个单位"L":左转 90 度"R":右转 90 度机器人按顺序执行指令 instructions,并一直重复它们。
只有在平面中存在环使得机器人永远无法离开时,返回 true。否则,返回 false。
+ +
示例 1:
+ +输入:"GGLLGG" +输出:true +解释: +机器人从 (0,0) 移动到 (0,2),转 180 度,然后回到 (0,0)。 +重复这些指令,机器人将保持在以原点为中心,2 为半径的环中进行移动。 ++ +
示例 2:
+ +输入:"GG" +输出:false +解释: +机器人无限向北移动。 ++ +
示例 3:
+ +输入:"GL" +输出:true +解释: +机器人按 (0, 0) -> (0, 1) -> (-1, 1) -> (-1, 0) -> (0, 0) -> ... 进行移动。+ +
+ +
提示:
+ +1 <= instructions.length <= 100instructions[i] 在 {'G', 'L', 'R'} 中有 n 个花园,按从 1 到 n 标记。另有数组 paths ,其中 paths[i] = [xi, yi] 描述了花园 xi 到花园 yi 的双向路径。在每个花园中,你打算种下四种花之一。
另外,所有花园 最多 有 3 条路径可以进入或离开.
+ +你需要为每个花园选择一种花,使得通过路径相连的任何两个花园中的花的种类互不相同。
+ +以数组形式返回 任一 可行的方案作为答案 answer,其中 answer[i] 为在第 (i+1) 个花园中种植的花的种类。花的种类用 1、2、3、4 表示。保证存在答案。
+ +
示例 1:
+ ++输入:n = 3, paths = [[1,2],[2,3],[3,1]] +输出:[1,2,3] +解释: +花园 1 和 2 花的种类不同。 +花园 2 和 3 花的种类不同。 +花园 3 和 1 花的种类不同。 +因此,[1,2,3] 是一个满足题意的答案。其他满足题意的答案有 [1,2,4]、[1,4,2] 和 [3,2,1] ++ +
示例 2:
+ ++输入:n = 4, paths = [[1,2],[3,4]] +输出:[1,2,1,2] ++ +
示例 3:
+ ++输入:n = 4, paths = [[1,2],[2,3],[3,4],[4,1],[1,3],[2,4]] +输出:[1,2,3,4] ++ +
+ +
提示:
+ +1 <= n <= 1040 <= paths.length <= 2 * 104paths[i].length == 21 <= xi, yi <= nxi != yi给你一个整数数组 arr,请你将该数组分隔为长度最多为 k 的一些(连续)子数组。分隔完成后,每个子数组的中的所有值都会变为该子数组中的最大值。
返回将数组分隔变换后能够得到的元素最大和。
+ ++ +
注意,原数组和分隔后的数组对应顺序应当一致,也就是说,你只能选择分隔数组的位置而不能调整数组中的顺序。
+ ++ +
示例 1:
+ ++输入:arr = [1,15,7,9,2,5,10], k = 3 +输出:84 +解释: +因为 k=3 可以分隔成 [1,15,7] [9] [2,5,10],结果为 [15,15,15,9,10,10,10],和为 84,是该数组所有分隔变换后元素总和最大的。 +若是分隔成 [1] [15,7,9] [2,5,10],结果就是 [1, 15, 15, 15, 10, 10, 10] 但这种分隔方式的元素总和(76)小于上一种。+ +
示例 2:
+ ++输入:arr = [1,4,1,5,7,3,6,1,9,9,3], k = 4 +输出:83 ++ +
示例 3:
+ ++输入:arr = [1], k = 1 +输出:1 ++ +
+ +
提示:
+ +1 <= arr.length <= 5000 <= arr[i] <= 1091 <= k <= arr.length给出一个字符串 S,考虑其所有重复子串(S 的连续子串,出现两次或多次,可能会有重叠)。
返回任何具有最长可能长度的重复子串。(如果 S 不含重复子串,那么答案为 ""。)
+ +
示例 1:
+ +输入:"banana" +输出:"ana" ++ +
示例 2:
+ +输入:"abcd" +输出:"" ++ +
+ +
提示:
+ +2 <= S.length <= 10^5S 由小写英文字母组成。有一堆石头,每块石头的重量都是正整数。
+ +每一回合,从中选出两块 最重的 石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
x == y,那么两块石头都会被完全粉碎;x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
+ +
示例:
+ ++输入:[2,7,4,1,8,1] +输出:1 +解释: +先选出 7 和 8,得到 1,所以数组转换为 [2,4,1,1,1], +再选出 2 和 4,得到 2,所以数组转换为 [2,1,1,1], +接着是 2 和 1,得到 1,所以数组转换为 [1,1,1], +最后选出 1 和 1,得到 0,最终数组转换为 [1],这就是最后剩下那块石头的重量。+ +
+ +
提示:
+ +1 <= stones.length <= 301 <= stones[i] <= 1000给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
+ +在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
+ ++ +
示例:
+ +输入:"abbaca" +输出:"ca" +解释: +例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。 ++ +
+ +
提示:
+ +1 <= S.length <= 20000S 仅由小写英文字母组成。给出一个单词列表,其中每个单词都由小写英文字母组成。
+ +如果我们可以在 word1 的任何地方添加一个字母使其变成 word2,那么我们认为 word1 是 word2 的前身。例如,"abc" 是 "abac" 的前身。
词链是单词 [word_1, word_2, ..., word_k] 组成的序列,k >= 1,其中 word_1 是 word_2 的前身,word_2 是 word_3 的前身,依此类推。
从给定单词列表 words 中选择单词组成词链,返回词链的最长可能长度。
+
示例:
+ +输入:["a","b","ba","bca","bda","bdca"] +输出:4 +解释:最长单词链之一为 "a","ba","bda","bdca"。 ++ +
+ +
提示:
+ +1 <= words.length <= 10001 <= words[i].length <= 16words[i] 仅由小写英文字母组成。diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/117_\346\235\250\350\276\211\344\270\211\350\247\222/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/117_\346\235\250\350\276\211\344\270\211\350\247\222/desc.html" new file mode 100644 index 0000000000000000000000000000000000000000..cf30c7436f10958952f3ceed00823041def41a23 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/117_\346\235\250\350\276\211\344\270\211\350\247\222/desc.html" @@ -0,0 +1,29 @@ +
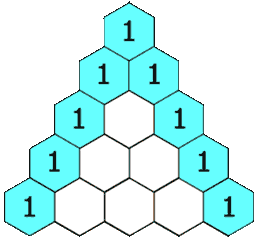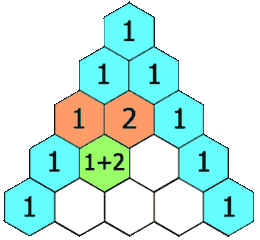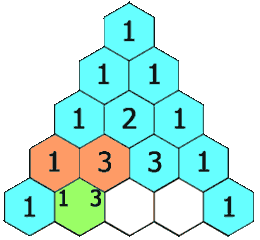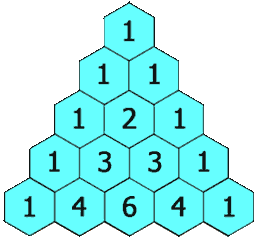
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。
在「杨辉三角」中,每个数是它左上方和右上方的数的和。
+ +
+ +
示例 1:
+ ++输入: numRows = 5 +输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]] ++ +
示例 2:
+ ++输入: numRows = 1 +输出: [[1]] ++ +
+ +
提示:
+ +1 <= numRows <= 30给你一个以二进制形式表示的数字 s 。请你返回按下述规则将其减少到 1 所需要的步骤数:
如果当前数字为偶数,则将其除以 2 。
+如果当前数字为奇数,则将其加上 1 。
+题目保证你总是可以按上述规则将测试用例变为 1 。
+ ++ +
示例 1:
+ +输入:s = "1101" +输出:6 +解释:"1101" 表示十进制数 13 。 +Step 1) 13 是奇数,加 1 得到 14 +Step 2) 14 是偶数,除 2 得到 7 +Step 3) 7 是奇数,加 1 得到 8 +Step 4) 8 是偶数,除 2 得到 4 +Step 5) 4 是偶数,除 2 得到 2 +Step 6) 2 是偶数,除 2 得到 1 ++ +
示例 2:
+ +输入:s = "10" +输出:1 +解释:"10" 表示十进制数 2 。 +Step 1) 2 是偶数,除 2 得到 1 ++ +
示例 3:
+ +输入:s = "1" +输出:0 ++ +
+ +
提示:
+ +1 <= s.length <= 500s 由字符 '0' 或 '1' 组成。s[0] == '1'我们称一个分割整数数组的方案是 好的 ,当它满足:
+ +left , mid , right 。left 中元素和小于等于 mid 中元素和,mid 中元素和小于等于 right 中元素和。给你一个 非负 整数数组 nums ,请你返回 好的 分割 nums 方案数目。由于答案可能会很大,请你将结果对 109 + 7 取余后返回。
+ +
示例 1:
+ ++输入:nums = [1,1,1] +输出:1 +解释:唯一一种好的分割方案是将 nums 分成 [1] [1] [1] 。+ +
示例 2:
+ ++输入:nums = [1,2,2,2,5,0] +输出:3 +解释:nums 总共有 3 种好的分割方案: +[1] [2] [2,2,5,0] +[1] [2,2] [2,5,0] +[1,2] [2,2] [5,0] ++ +
示例 3:
+ ++输入:nums = [3,2,1] +输出:0 +解释:没有好的分割方案。+ +
+ +
提示:
+ +3 <= nums.length <= 1050 <= nums[i] <= 104给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
注意:该题与 1081 https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters 相同
+ ++ +
示例 1:
+ ++输入:+ +s = "bcabc"+输出:"abc"+
示例 2:
+ ++输入:+ +s = "cbacdcbc"+输出:"acdb"
+ +
提示:
+ +1 <= s.length <= 104s 由小写英文字母组成给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
+ +示例 1:
+ +输入: +nums1 =+ +[3, 4, 6, 5]+nums2 =[9, 1, 2, 5, 8, 3]+k =5+输出: +[9, 8, 6, 5, 3]
示例 2:
+ +输入: +nums1 =+ +[6, 7]+nums2 =[6, 0, 4]+k =5+输出: +[6, 7, 6, 0, 4]
示例 3:
+ +输入: +nums1 =diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/321_\351\233\266\351\222\261\345\205\221\346\215\242/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/321_\351\233\266\351\222\261\345\205\221\346\215\242/desc.html" new file mode 100644 index 0000000000000000000000000000000000000000..9998f26894f38bf5a522a57d44f06a68d1bba6ba --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/321_\351\233\266\351\222\261\345\205\221\346\215\242/desc.html" @@ -0,0 +1,51 @@ +[3, 9]+nums2 =[8, 9]+k =3+输出: +[9, 8, 9]
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
+ ++ +
示例 1:
+ ++输入:coins =+ +[1, 2, 5], amount =11+输出:3+解释:11 = 5 + 5 + 1
示例 2:
+ ++输入:coins =+ +[2], amount =3+输出:-1
示例 3:
+ ++输入:coins = [1], amount = 0 +输出:0 ++ +
示例 4:
+ ++输入:coins = [1], amount = 1 +输出:1 ++ +
示例 5:
+ ++输入:coins = [1], amount = 2 +输出:2 ++ +
+ +
提示:
+ +1 <= coins.length <= 121 <= coins[i] <= 231 - 10 <= amount <= 104给定一个整数,写一个函数来判断它是否是 3 的幂次方。如果是,返回 true ;否则,返回 false 。
整数 n 是 3 的幂次方需满足:存在整数 x 使得 n == 3x
+ +
示例 1:
+ ++输入:n = 27 +输出:true ++ +
示例 2:
+ ++输入:n = 0 +输出:false ++ +
示例 3:
+ ++输入:n = 9 +输出:true ++ +
示例 4:
+ ++输入:n = 45 +输出:false ++ +
+ +
提示:
+ +-231 <= n <= 231 - 1+ +
进阶:
+ +给你一个整数数组 nums 以及两个整数 lower 和 upper 。求数组中,值位于范围 [lower, upper] (包含 lower 和 upper)之内的 区间和的个数 。
区间和 S(i, j) 表示在 nums 中,位置从 i 到 j 的元素之和,包含 i 和 j (i ≤ j)。
+示例 1: + +
+输入:nums = [-2,5,-1], lower = -2, upper = 2 +输出:3 +解释:存在三个区间:[0,0]、[2,2] 和 [0,2] ,对应的区间和分别是:-2 、-1 、2 。 ++ +
示例 2:
+ ++输入:nums = [0], lower = 0, upper = 0 +输出:1 ++ +
+ +
提示:
+ +1 <= nums.length <= 105-231 <= nums[i] <= 231 - 1-105 <= lower <= upper <= 105序列化二叉树的一种方法是使用前序遍历。当我们遇到一个非空节点时,我们可以记录下这个节点的值。如果它是一个空节点,我们可以使用一个标记值记录,例如 #。
_9_ + / \ + 3 2 + / \ / \ + 4 1 # 6 +/ \ / \ / \ +# # # # # # ++ +
例如,上面的二叉树可以被序列化为字符串 "9,3,4,#,#,1,#,#,2,#,6,#,#",其中 # 代表一个空节点。
给定一串以逗号分隔的序列,验证它是否是正确的二叉树的前序序列化。编写一个在不重构树的条件下的可行算法。
+ +每个以逗号分隔的字符或为一个整数或为一个表示 null 指针的 '#' 。
你可以认为输入格式总是有效的,例如它永远不会包含两个连续的逗号,比如 "1,,3" 。
示例 1:
+ +输入:+ +"9,3,4,#,#,1,#,#,2,#,6,#,#"+输出:true
示例 2:
+ +输入:+ +"1,#"+输出:false+
示例 3:
+ +输入:diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/333_\351\200\222\345\242\236\347\232\204\344\270\211\345\205\203\345\255\220\345\272\217\345\210\227/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/333_\351\200\222\345\242\236\347\232\204\344\270\211\345\205\203\345\255\220\345\272\217\345\210\227/desc.html" new file mode 100644 index 0000000000000000000000000000000000000000..d5f5888225368870c9c2153b6e0b1b0794ceedc1 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/333_\351\200\222\345\242\236\347\232\204\344\270\211\345\205\203\345\255\220\345\272\217\345\210\227/desc.html" @@ -0,0 +1,41 @@ +"9,#,#,1"+输出:false
给你一个整数数组 nums ,判断这个数组中是否存在长度为 3 的递增子序列。
如果存在这样的三元组下标 (i, j, k) 且满足 i < j < k ,使得 nums[i] < nums[j] < nums[k] ,返回 true ;否则,返回 false 。
+ +
示例 1:
+ ++输入:nums = [1,2,3,4,5] +输出:true +解释:任何 i < j < k 的三元组都满足题意 ++ +
示例 2:
+ ++输入:nums = [5,4,3,2,1] +输出:false +解释:不存在满足题意的三元组+ +
示例 3:
+ ++输入:nums = [2,1,5,0,4,6] +输出:true +解释:三元组 (3, 4, 5) 满足题意,因为 nums[3] == 0 < nums[4] == 4 < nums[5] == 6 ++ +
+ +
提示:
+ +1 <= nums.length <= 105-231 <= nums[i] <= 231 - 1+ +
进阶:你能实现时间复杂度为 O(n) ,空间复杂度为 O(1) 的解决方案吗?
给定平面上 n 对 互不相同 的点 points ,其中 points[i] = [xi, yi] 。回旋镖 是由点 (i, j, k) 表示的元组 ,其中 i 和 j 之间的距离和 i 和 k 之间的欧式距离相等(需要考虑元组的顺序)。
返回平面上所有回旋镖的数量。
+ + +示例 1:
+ ++输入:points = [[0,0],[1,0],[2,0]] +输出:2 +解释:两个回旋镖为 [[1,0],[0,0],[2,0]] 和 [[1,0],[2,0],[0,0]] ++ +
示例 2:
+ ++输入:points = [[1,1],[2,2],[3,3]] +输出:2 ++ +
示例 3:
+ ++输入:points = [[1,1]] +输出:0 ++ +
+ +
提示:
+ +n == points.length1 <= n <= 500points[i].length == 2-104 <= xi, yi <= 104给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1, n] 内。请你找出所有在 [1, n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。
+ +
示例 1:
+ ++输入:nums = [4,3,2,7,8,2,3,1] +输出:[5,6] ++ +
示例 2:
+ ++输入:nums = [1,1] +输出:[2] ++ +
+ +
提示:
+ +n == nums.length1 <= n <= 1051 <= nums[i] <= n进阶:你能在不使用额外空间且时间复杂度为 O(n) 的情况下解决这个问题吗? 你可以假定返回的数组不算在额外空间内。
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以纵坐标并不重要,因此只要知道开始和结束的横坐标就足够了。开始坐标总是小于结束坐标。
+ +一支弓箭可以沿着 x 轴从不同点完全垂直地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
给你一个数组 points ,其中 points [i] = [xstart,xend] ,返回引爆所有气球所必须射出的最小弓箭数。
示例 1:
+ ++输入:points = [[10,16],[2,8],[1,6],[7,12]] +输出:2 +解释:对于该样例,x = 6 可以射爆 [2,8],[1,6] 两个气球,以及 x = 11 射爆另外两个气球+ +
示例 2:
+ ++输入:points = [[1,2],[3,4],[5,6],[7,8]] +输出:4 ++ +
示例 3:
+ ++输入:points = [[1,2],[2,3],[3,4],[4,5]] +输出:2 ++ +
示例 4:
+ ++输入:points = [[1,2]] +输出:1 ++ +
示例 5:
+ ++输入:points = [[2,3],[2,3]] +输出:1 ++ +
+ +
提示:
+ +1 <= points.length <= 104points[i].length == 2-231 <= xstart < xend <= 231 - 1给你一个长度为 n 的整数数组,每次操作将会使 n - 1 个元素增加 1 。返回让数组所有元素相等的最小操作次数。
+ +
示例 1:
+ ++输入:nums = [1,2,3] +输出:3 +解释: +只需要3次操作(注意每次操作会增加两个元素的值): +[1,2,3] => [2,3,3] => [3,4,3] => [4,4,4] ++ +
示例 2:
+ ++输入:nums = [1,1,1] +输出:0 ++ +
+ +
提示:
+ +n == nums.length1 <= nums.length <= 105-109 <= nums[i] <= 109假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
+ +对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
+ ++输入: g = [1,2,3], s = [1,1] +输出: 1 +解释: +你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。 +虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。 +所以你应该输出1。 ++ +
示例 2:
+ ++输入: g = [1,2], s = [1,2,3] +输出: 2 +解释: +你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。 +你拥有的饼干数量和尺寸都足以让所有孩子满足。 +所以你应该输出2. ++ +
+ +
提示:
+ +1 <= g.length <= 3 * 1040 <= s.length <= 3 * 1041 <= g[i], s[j] <= 231 - 1给你一个整数数组 nums ,数组中共有 n 个整数。132 模式的子序列 由三个整数 nums[i]、nums[j] 和 nums[k] 组成,并同时满足:i < j < k 和 nums[i] < nums[k] < nums[j] 。
如果 nums 中存在 132 模式的子序列 ,返回 true ;否则,返回 false 。
+ +
示例 1:
+ ++输入:nums = [1,2,3,4] +输出:false +解释:序列中不存在 132 模式的子序列。 ++ +
示例 2:
+ ++输入:nums = [3,1,4,2] +输出:true +解释:序列中有 1 个 132 模式的子序列: [1, 4, 2] 。 ++ +
示例 3:
+ ++输入:nums = [-1,3,2,0] +输出:true +解释:序列中有 3 个 132 模式的的子序列:[-1, 3, 2]、[-1, 3, 0] 和 [-1, 2, 0] 。 ++ +
+ +
提示:
+ +n == nums.length1 <= n <= 2 * 105-109 <= nums[i] <= 109有 buckets 桶液体,其中 正好 有一桶含有毒药,其余装的都是水。它们从外观看起来都一样。为了弄清楚哪只水桶含有毒药,你可以喂一些猪喝,通过观察猪是否会死进行判断。不幸的是,你只有 minutesToTest 分钟时间来确定哪桶液体是有毒的。
喂猪的规则如下:
+ +minutesToDie 分钟的冷却时间。在这段时间里,你只能观察,而不允许继续喂猪。minutesToDie 分钟后,所有喝到毒药的猪都会死去,其他所有猪都会活下来。给你桶的数目 buckets ,minutesToDie 和 minutesToTest ,返回在规定时间内判断哪个桶有毒所需的 最小 猪数。
+ +
示例 1:
+ ++输入:buckets = 1000, minutesToDie = 15, minutesToTest = 60 +输出:5 ++ +
示例 2:
+ ++输入:buckets = 4, minutesToDie = 15, minutesToTest = 15 +输出:2 ++ +
示例 3:
+ ++输入:buckets = 4, minutesToDie = 15, minutesToTest = 30 +输出:2 ++ +
+ +
提示:
+ +1 <= buckets <= 10001 <= minutesToDie <= minutesToTest <= 100集合 s 包含从 1 到 n 的整数。不幸的是,因为数据错误,导致集合里面某一个数字复制了成了集合里面的另外一个数字的值,导致集合 丢失了一个数字 并且 有一个数字重复 。
给定一个数组 nums 代表了集合 S 发生错误后的结果。
请你找出重复出现的整数,再找到丢失的整数,将它们以数组的形式返回。
+ ++ +
示例 1:
+ ++输入:nums = [1,2,2,4] +输出:[2,3] ++ +
示例 2:
+ ++输入:nums = [1,1] +输出:[1,2] ++ +
+ +
提示:
+ +2 <= nums.length <= 1041 <= nums[i] <= 104给出 n 个数对。 在每一个数对中,第一个数字总是比第二个数字小。
现在,我们定义一种跟随关系,当且仅当 b < c 时,数对(c, d) 才可以跟在 (a, b) 后面。我们用这种形式来构造一个数对链。
给定一个数对集合,找出能够形成的最长数对链的长度。你不需要用到所有的数对,你可以以任何顺序选择其中的一些数对来构造。
+ ++ +
示例:
+ ++输入:[[1,2], [2,3], [3,4]] +输出:2 +解释:最长的数对链是 [1,2] -> [3,4] ++ +
+ +
提示:
+ +[1, 1000] 范围内。给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。
回文字符串 是正着读和倒过来读一样的字符串。
+ +子字符串 是字符串中的由连续字符组成的一个序列。
+ +具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
+ ++ +
示例 1:
+ ++输入:s = "abc" +输出:3 +解释:三个回文子串: "a", "b", "c" ++ +
示例 2:
+ ++输入:s = "aaa" +输出:6 +解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa"+ +
+ +
提示:
+ +1 <= s.length <= 1000s 由小写英文字母组成Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇)
Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的一项:
禁止一名参议员的权利:
参议员可以让另一位参议员在这一轮和随后的几轮中丧失所有的权利。
+宣布胜利:
如果参议员发现有权利投票的参议员都是同一个阵营的,他可以宣布胜利并决定在游戏中的有关变化。
+ ++ +
给定一个字符串代表每个参议员的阵营。字母 “R” 和 “D” 分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 n 个参议员,给定字符串的大小将是 n。
以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
+ +假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 Radiant 或 Dire。
+ +
示例 1:
+ +
+输入:"RD"
+输出:"Radiant"
+解释:第一个参议员来自 Radiant 阵营并且他可以使用第一项权利让第二个参议员失去权力,因此第二个参议员将被跳过因为他没有任何权利。然后在第二轮的时候,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人
+
+
+示例 2:
+ ++输入:"RDD" +输出:"Dire" +解释: +第一轮中,第一个+ +来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利 +第二个来自 Dire 阵营的参议员会被跳过因为他的权利被禁止 +第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利 +因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利 +
+ +
提示:
+ +[1, 10,000] 之间.diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/649_\345\217\252\346\234\211\344\270\244\344\270\252\351\224\256\347\232\204\351\224\256\347\233\230/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/649_\345\217\252\346\234\211\344\270\244\344\270\252\351\224\256\347\232\204\351\224\256\347\233\230/desc.html" new file mode 100644 index 0000000000000000000000000000000000000000..538b623178daa9f086303fb0a7d552eef36170e5 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/649_\345\217\252\346\234\211\344\270\244\344\270\252\351\224\256\347\232\204\351\224\256\347\233\230/desc.html" @@ -0,0 +1,37 @@ +
最初记事本上只有一个字符 'A' 。你每次可以对这个记事本进行两种操作:
Copy All(复制全部):复制这个记事本中的所有字符(不允许仅复制部分字符)。Paste(粘贴):粘贴 上一次 复制的字符。给你一个数字 n ,你需要使用最少的操作次数,在记事本上输出 恰好 n 个 'A' 。返回能够打印出 n 个 'A' 的最少操作次数。
+ +
示例 1:
+ ++输入:3 +输出:3 +解释: +最初, 只有一个字符 'A'。 +第 1 步, 使用 Copy All 操作。 +第 2 步, 使用 Paste 操作来获得 'AA'。 +第 3 步, 使用 Paste 操作来获得 'AAA'。 ++ +
示例 2:
+ ++输入:n = 1 +输出:0 ++ +
+ +
提示:
+ +1 <= n <= 1000给定一棵二叉树,返回所有重复的子树。对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可。
+ +两棵树重复是指它们具有相同的结构以及相同的结点值。
+ +示例 1:
+ +1 + / \ + 2 3 + / / \ + 4 2 4 + / + 4 ++ +
下面是两个重复的子树:
+ +2 + / + 4 ++ +
和
+ +4 ++ +
因此,你需要以列表的形式返回上述重复子树的根结点。
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/652_\344\270\244\346\225\260\344\271\213\345\222\214 IV - \350\276\223\345\205\245 BST/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/652_\344\270\244\346\225\260\344\271\213\345\222\214 IV - \350\276\223\345\205\245 BST/desc.html" new file mode 100644 index 0000000000000000000000000000000000000000..5d77c55a8b0c01630d14996eee52f17a923f8ee2 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/652_\344\270\244\346\225\260\344\271\213\345\222\214 IV - \350\276\223\345\205\245 BST/desc.html" @@ -0,0 +1,49 @@ +给定一个二叉搜索树 root 和一个目标结果 k,如果 BST 中存在两个元素且它们的和等于给定的目标结果,则返回 true。
+ +
示例 1:
+ +
++输入: root = [5,3,6,2,4,null,7], k = 9 +输出: true ++ +
示例 2:
+ +
++输入: root = [5,3,6,2,4,null,7], k = 28 +输出: false ++ +
示例 3:
+ ++输入: root = [2,1,3], k = 4 +输出: true ++ +
示例 4:
+ ++输入: root = [2,1,3], k = 1 +输出: false ++ +
示例 5:
+ ++输入: root = [2,1,3], k = 3 +输出: true ++ +
+ +
提示:
+ +[1, 104].-104 <= Node.val <= 104root 为二叉搜索树-105 <= k <= 105给定一副牌,每张牌上都写着一个整数。
+ +此时,你需要选定一个数字 X,使我们可以将整副牌按下述规则分成 1 组或更多组:
X 张牌。仅当你可选的 X >= 2 时返回 true。
+ +
示例 1:
+ +输入:[1,2,3,4,4,3,2,1] +输出:true +解释:可行的分组是 [1,1],[2,2],[3,3],[4,4] ++ +
示例 2:
+ +输入:[1,1,1,2,2,2,3,3] +输出:false +解释:没有满足要求的分组。 ++ +
示例 3:
+ +输入:[1] +输出:false +解释:没有满足要求的分组。 ++ +
示例 4:
+ +输入:[1,1] +输出:true +解释:可行的分组是 [1,1] ++ +
示例 5:
+ +输入:[1,1,2,2,2,2] +输出:true +解释:可行的分组是 [1,1],[2,2],[2,2] ++ +
+提示:
1 <= deck.length <= 100000 <= deck[i] < 10000diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/914_\345\210\206\345\211\262\346\225\260\347\273\204/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/914_\345\210\206\345\211\262\346\225\260\347\273\204/desc.html" new file mode 100644 index 0000000000000000000000000000000000000000..90ba882896c795140e3a83c9f51aa09bccf54ef9 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/914_\345\210\206\345\211\262\346\225\260\347\273\204/desc.html" @@ -0,0 +1,39 @@ +
给定一个数组 A,将其划分为两个连续子数组 left 和 right, 使得:
left 中的每个元素都小于或等于 right 中的每个元素。left 和 right 都是非空的。left 的长度要尽可能小。在完成这样的分组后返回 left 的长度。可以保证存在这样的划分方法。
+ +
示例 1:
+ ++输入:[5,0,3,8,6] +输出:3 +解释:left = [5,0,3],right = [8,6] ++ +
示例 2:
+ ++输入:[1,1,1,0,6,12] +输出:4 +解释:left = [1,1,1,0],right = [6,12] ++ +
+ +
提示:
+ +2 <= A.length <= 300000 <= A[i] <= 10^6A 进行划分。diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/915_\345\215\225\350\257\215\345\255\220\351\233\206/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/915_\345\215\225\350\257\215\345\255\220\351\233\206/desc.html" new file mode 100644 index 0000000000000000000000000000000000000000..439e86621b841665b6eefe65b88559f2101b593e --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/915_\345\215\225\350\257\215\345\255\220\351\233\206/desc.html" @@ -0,0 +1,53 @@ +
我们给出两个单词数组 A 和 B。每个单词都是一串小写字母。
现在,如果 b 中的每个字母都出现在 a 中,包括重复出现的字母,那么称单词 b 是单词 a 的子集。 例如,“wrr” 是 “warrior” 的子集,但不是 “world” 的子集。
如果对 B 中的每一个单词 b,b 都是 a 的子集,那么我们称 A 中的单词 a 是通用的。
你可以按任意顺序以列表形式返回 A 中所有的通用单词。
+ +
示例 1:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["e","o"] +输出:["facebook","google","leetcode"] ++ +
示例 2:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["l","e"] +输出:["apple","google","leetcode"] ++ +
示例 3:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["e","oo"] +输出:["facebook","google"] ++ +
示例 4:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["lo","eo"] +输出:["google","leetcode"] ++ +
示例 5:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["ec","oc","ceo"] +输出:["facebook","leetcode"] ++ +
+ +
提示:
+ +1 <= A.length, B.length <= 100001 <= A[i].length, B[i].length <= 10A[i] 和 B[i] 只由小写字母组成。A[i] 中所有的单词都是独一无二的,也就是说不存在 i != j 使得 A[i] == A[j]。完全二叉树是每一层(除最后一层外)都是完全填充(即,节点数达到最大)的,并且所有的节点都尽可能地集中在左侧。
+ +设计一个用完全二叉树初始化的数据结构 CBTInserter,它支持以下几种操作:
CBTInserter(TreeNode root) 使用头节点为 root 的给定树初始化该数据结构;CBTInserter.insert(int v) 向树中插入一个新节点,节点类型为 TreeNode,值为 v 。使树保持完全二叉树的状态,并返回插入的新节点的父节点的值;CBTInserter.get_root() 将返回树的头节点。+ +
示例 1:
+ +输入:inputs = ["CBTInserter","insert","get_root"], inputs = [[[1]],[2],[]] +输出:[null,1,[1,2]] ++ +
示例 2:
+ +输入:inputs = ["CBTInserter","insert","insert","get_root"], inputs = [[[1,2,3,4,5,6]],[7],[8],[]] +输出:[null,3,4,[1,2,3,4,5,6,7,8]] ++ +
+ +
提示:
+ +1 到 1000 个节点。CBTInserter.insert 操作 10000 次。0 到 5000 之间。你的音乐播放器里有 N 首不同的歌,在旅途中,你的旅伴想要听 L 首歌(不一定不同,即,允许歌曲重复)。请你为她按如下规则创建一个播放列表:
K 首歌播放完之后才能再次播放。返回可以满足要求的播放列表的数量。由于答案可能非常大,请返回它模 10^9 + 7 的结果。
+ +
示例 1:
+ +输入:N = 3, L = 3, K = 1 +输出:6 +解释:有 6 种可能的播放列表。[1, 2, 3],[1, 3, 2],[2, 1, 3],[2, 3, 1],[3, 1, 2],[3, 2, 1]. ++ +
示例 2:
+ +输入:N = 2, L = 3, K = 0 +输出:6 +解释:有 6 种可能的播放列表。[1, 1, 2],[1, 2, 1],[2, 1, 1],[2, 2, 1],[2, 1, 2],[1, 2, 2] ++ +
示例 3:
+ +输入:N = 2, L = 3, K = 1 +输出:2 +解释:有 2 种可能的播放列表。[1, 2, 1],[2, 1, 2] ++ +
+ +
提示:
+ +0 <= K < N <= L <= 100给定一个由 '(' 和 ')' 括号组成的字符串 S,我们需要添加最少的括号( '(' 或是 ')',可以在任何位置),以使得到的括号字符串有效。
从形式上讲,只有满足下面几点之一,括号字符串才是有效的:
+ +AB (A 与 B 连接), 其中 A 和 B 都是有效字符串,或者(A),其中 A 是有效字符串。给定一个括号字符串,返回为使结果字符串有效而必须添加的最少括号数。
+ ++ +
示例 1:
+ +输入:"())" +输出:1 ++ +
示例 2:
+ +输入:"((("
+输出:3
+
+
+示例 3:
+ +输入:"()" +输出:0 ++ +
示例 4:
+ +输入:"()))(("
+输出:4
+
++ +
提示:
+ +S.length <= 1000S 只包含 '(' 和 ')' 字符。diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/921_\346\214\211\345\245\207\345\201\266\346\216\222\345\272\217\346\225\260\347\273\204 II/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/921_\346\214\211\345\245\207\345\201\266\346\216\222\345\272\217\346\225\260\347\273\204 II/desc.html" new file mode 100644 index 0000000000000000000000000000000000000000..3ec0c586f074d266ffc7d62f9c3f2250ee05ed99 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/921_\346\214\211\345\245\207\345\201\266\346\216\222\345\272\217\346\225\260\347\273\204 II/desc.html" @@ -0,0 +1,26 @@ +
给定一个非负整数数组 A, A 中一半整数是奇数,一半整数是偶数。
对数组进行排序,以便当 A[i] 为奇数时,i 也是奇数;当 A[i] 为偶数时, i 也是偶数。
你可以返回任何满足上述条件的数组作为答案。
+ ++ +
示例:
+ +输入:[4,2,5,7] +输出:[4,5,2,7] +解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。 ++ +
+ +
提示:
+ +2 <= A.length <= 20000A.length % 2 == 00 <= A[i] <= 1000diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/923_\345\260\275\351\207\217\345\207\217\345\260\221\346\201\266\346\204\217\350\275\257\344\273\266\347\232\204\344\274\240\346\222\255/desc.html" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/923_\345\260\275\351\207\217\345\207\217\345\260\221\346\201\266\346\204\217\350\275\257\344\273\266\347\232\204\344\274\240\346\222\255/desc.html" new file mode 100644 index 0000000000000000000000000000000000000000..9b6ca849993edb3e456a23618f27e71b034f9c5f --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode/923_\345\260\275\351\207\217\345\207\217\345\260\221\346\201\266\346\204\217\350\275\257\344\273\266\347\232\204\344\274\240\346\222\255/desc.html" @@ -0,0 +1,47 @@ +
在节点网络中,只有当 graph[i][j] = 1 时,每个节点 i 能够直接连接到另一个节点 j。
一些节点 initial 最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。
假设 M(initial) 是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。
如果从初始列表中移除某一节点能够最小化 M(initial), 返回该节点。如果有多个节点满足条件,就返回索引最小的节点。
请注意,如果某个节点已从受感染节点的列表 initial 中删除,它以后可能仍然因恶意软件传播而受到感染。
+ +
示例 1:
+ ++输入:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1] +输出:0 ++ +
示例 2:
+ ++输入:graph = [[1,0,0],[0,1,0],[0,0,1]], initial = [0,2] +输出:0 ++ +
示例 3:
+ ++输入:graph = [[1,1,1],[1,1,1],[1,1,1]], initial = [1,2] +输出:1 ++ +
+ +
提示:
+ +1 < graph.length = graph[0].length <= 3000 <= graph[i][j] == graph[j][i] <= 1graph[i][i] == 11 <= initial.length < graph.length0 <= initial[i] < graph.length(这个问题与 尽量减少恶意软件的传播 是一样的,不同之处用粗体表示。)
+ +在节点网络中,只有当 graph[i][j] = 1 时,每个节点 i 能够直接连接到另一个节点 j。
一些节点 initial 最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。
假设 M(initial) 是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。
我们可以从初始列表中删除一个节点,并完全移除该节点以及从该节点到任何其他节点的任何连接。如果移除这一节点将最小化 M(initial), 则返回该节点。如果有多个节点满足条件,就返回索引最小的节点。
+ +
示例 1:
+ +输出:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1] +输入:0 ++ +
示例 2:
+ +输入:graph = [[1,1,0],[1,1,1],[0,1,1]], initial = [0,1] +输出:1 ++ +
示例 3:
+ +输入:graph = [[1,1,0,0],[1,1,1,0],[0,1,1,1],[0,0,1,1]], initial = [0,1] +输出:1 ++ +
+ +
提示:
+ +1 < graph.length = graph[0].length <= 3000 <= graph[i][j] == graph[j][i] <= 1graph[i][i] = 11 <= initial.length < graph.length0 <= initial[i] < graph.length