给定一个二叉树,返回其节点值的锯齿形层序遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
+ +例如:
+给定二叉树 [3,9,20,null,null,15,7],
+ 3 + / \ + 9 20 + / \ + 15 7 ++ +
返回锯齿形层序遍历如下:
+ ++[ + [3], + [20,9], + [15,7] +] ++ +
以下错误的选项是?
+ +## aop +### before +```cpp +#include给定一个二叉树,检查它是否是镜像对称的。
+ ++ +
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1 + / \ + 2 2 + / \ / \ +3 4 4 3 ++ +
+ +
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1 + / \ + 2 2 + \ \ + 3 3 ++ +
+ +
进阶:
+ +你可以运用递归和迭代两种方法解决这个问题吗?
diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode-\346\240\221/8.101-\345\257\271\347\247\260\344\272\214\345\217\211\346\240\221/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode-\346\240\221/8.101-\345\257\271\347\247\260\344\272\214\345\217\211\346\240\221/solution.cpp" new file mode 100644 index 0000000000000000000000000000000000000000..866185798b25413bb71cfa61931a3d0ef9a2299f --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode-\346\240\221/8.101-\345\257\271\347\247\260\344\272\214\345\217\211\346\240\221/solution.cpp" @@ -0,0 +1,46 @@ +#include给定一个二叉树,检查它是否是镜像对称的。
+ ++ +
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1 + / \ + 2 2 + / \ / \ +3 4 4 3 ++ +
+ +
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1 + / \ + 2 2 + \ \ + 3 3 ++ +
+ +
进阶:
+ +你可以运用递归和迭代两种方法解决这个问题吗?
+ +以下错误的选项是?
+ +## aop +### before +```cpp +#include给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
+ ++ +
示例:
+二叉树:[3,9,20,null,null,15,7],
+ 3 + / \ + 9 20 + / \ + 15 7 ++ +
返回其层序遍历结果:
+ ++[ + [3], + [9,20], + [15,7] +] +diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode-\346\240\221/9.102-\344\272\214\345\217\211\346\240\221\347\232\204\345\261\202\345\272\217\351\201\215\345\216\206/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode-\346\240\221/9.102-\344\272\214\345\217\211\346\240\221\347\232\204\345\261\202\345\272\217\351\201\215\345\216\206/solution.cpp" new file mode 100644 index 0000000000000000000000000000000000000000..35ef92eada7dc73568d2a76991fe4bff4ac2430a --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/1.leetcode-\346\240\221/9.102-\344\272\214\345\217\211\346\240\221\347\232\204\345\261\202\345\272\217\351\201\215\345\216\206/solution.cpp" @@ -0,0 +1,43 @@ +#include
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
+ ++ +
示例:
+二叉树:[3,9,20,null,null,15,7],
+ 3 + / \ + 9 20 + / \ + 15 7 ++ +
返回其层序遍历结果:
+ ++[ + [3], + [9,20], + [15,7] +] ++ +
以下错误的选项是?
+ +## aop +### before +```cpp +#include给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以 字符串形式返回小数 。
如果小数部分为循环小数,则将循环的部分括在括号内。
+ +如果存在多个答案,只需返回 任意一个 。
+ +对于所有给定的输入,保证 答案字符串的长度小于 104 。
+ +
示例 1:
+ ++输入:numerator = 1, denominator = 2 +输出:"0.5" ++ +
示例 2:
+ ++输入:numerator = 2, denominator = 1 +输出:"2" ++ +
示例 3:
+ ++输入:numerator = 2, denominator = 3 +输出:"0.(6)" ++ +
示例 4:
+ ++输入:numerator = 4, denominator = 333 +输出:"0.(012)" ++ +
示例 5:
+ ++输入:numerator = 1, denominator = 5 +输出:"0.2" ++ +
+ +
提示:
+ +-
+
-231 <= numerator, denominator <= 231 - 1
+ denominator != 0
+
给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以 字符串形式返回小数 。
如果小数部分为循环小数,则将循环的部分括在括号内。
+ +如果存在多个答案,只需返回 任意一个 。
+ +对于所有给定的输入,保证 答案字符串的长度小于 104 。
+ +
示例 1:
+ ++输入:numerator = 1, denominator = 2 +输出:"0.5" ++ +
示例 2:
+ ++输入:numerator = 2, denominator = 1 +输出:"2" ++ +
示例 3:
+ ++输入:numerator = 2, denominator = 3 +输出:"0.(6)" ++ +
示例 4:
+ ++输入:numerator = 4, denominator = 333 +输出:"0.(012)" ++ +
示例 5:
+ ++输入:numerator = 1, denominator = 5 +输出:"0.2" ++ +
+ +
提示:
+ +-
+
-231 <= numerator, denominator <= 231 - 1
+ denominator != 0
+
以下错误的选项是?
+ +## aop +### before +```cpp +#include按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:
-
+
- 每对相邻的单词之间仅有单个字母不同。 +
- 转换过程中的每个单词
si(1 <= i <= k)必须是字典wordList中的单词。注意,beginWord不必是字典wordList中的单词。
+ sk == endWord
+
给你两个单词 beginWord 和 endWord ,以及一个字典 wordList 。请你找出并返回所有从 beginWord 到 endWord 的 最短转换序列 ,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表 [beginWord, s1, s2, ..., sk] 的形式返回。
+ +
示例 1:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] +输出:[["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]] +解释:存在 2 种最短的转换序列: +"hit" -> "hot" -> "dot" -> "dog" -> "cog" +"hit" -> "hot" -> "lot" -> "log" -> "cog" ++ +
示例 2:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] +输出:[] +解释:endWord "cog" 不在字典 wordList 中,所以不存在符合要求的转换序列。 ++ +
+ +
提示:
+ +-
+
1 <= beginWord.length <= 7
+ endWord.length == beginWord.length
+ 1 <= wordList.length <= 5000
+ wordList[i].length == beginWord.length
+ beginWord、endWord和wordList[i]由小写英文字母组成
+ beginWord != endWord
+ wordList中的所有单词 互不相同
+
按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:
-
+
- 每对相邻的单词之间仅有单个字母不同。 +
- 转换过程中的每个单词
si(1 <= i <= k)必须是字典wordList中的单词。注意,beginWord不必是字典wordList中的单词。
+ sk == endWord
+
给你两个单词 beginWord 和 endWord ,以及一个字典 wordList 。请你找出并返回所有从 beginWord 到 endWord 的 最短转换序列 ,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表 [beginWord, s1, s2, ..., sk] 的形式返回。
+ +
示例 1:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] +输出:[["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]] +解释:存在 2 种最短的转换序列: +"hit" -> "hot" -> "dot" -> "dog" -> "cog" +"hit" -> "hot" -> "lot" -> "log" -> "cog" ++ +
示例 2:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] +输出:[] +解释:endWord "cog" 不在字典 wordList 中,所以不存在符合要求的转换序列。 ++ +
+ +
提示:
+ +-
+
1 <= beginWord.length <= 7
+ endWord.length == beginWord.length
+ 1 <= wordList.length <= 5000
+ wordList[i].length == beginWord.length
+ beginWord、endWord和wordList[i]由小写英文字母组成
+ beginWord != endWord
+ wordList中的所有单词 互不相同
+
以下错误的选项是?
+ +## aop +### before +```cpp +#include字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
-
+
- 序列中第一个单词是
beginWord。
+ - 序列中最后一个单词是
endWord。
+ - 每次转换只能改变一个字母。 +
- 转换过程中的中间单词必须是字典
wordList中的单词。
+
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
示例 1:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] +输出:5 +解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。 ++ +
示例 2:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] +输出:0 +解释:endWord "cog" 不在字典中,所以无法进行转换。+ +
+ +
提示:
+ +-
+
1 <= beginWord.length <= 10
+ endWord.length == beginWord.length
+ 1 <= wordList.length <= 5000
+ wordList[i].length == beginWord.length
+ beginWord、endWord和wordList[i]由小写英文字母组成
+ beginWord != endWord
+ wordList中的所有字符串 互不相同
+
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列:
-
+
- 序列中第一个单词是
beginWord。
+ - 序列中最后一个单词是
endWord。
+ - 每次转换只能改变一个字母。 +
- 转换过程中的中间单词必须是字典
wordList中的单词。
+
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,找到从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0。
示例 1:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] +输出:5 +解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。 ++ +
示例 2:
+ ++输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] +输出:0 +解释:endWord "cog" 不在字典中,所以无法进行转换。+ +
+ +
提示:
+ +-
+
1 <= beginWord.length <= 10
+ endWord.length == beginWord.length
+ 1 <= wordList.length <= 5000
+ wordList[i].length == beginWord.length
+ beginWord、endWord和wordList[i]由小写英文字母组成
+ beginWord != endWord
+ wordList中的所有字符串 互不相同
+
以下错误的选项是?
+ +## aop +### before +```cpp +#include给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
+ +
示例 1:
+ +
+输入:nums = [100,4,200,1,3,2]
+输出:4
+解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
+
+示例 2:
+ ++输入:nums = [0,3,7,2,5,8,4,6,0,1] +输出:9 ++ +
+ +
提示:
+ +-
+
0 <= nums.length <= 105
+ -109 <= nums[i] <= 109
+
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
+ +
示例 1:
+ +
+输入:nums = [100,4,200,1,3,2]
+输出:4
+解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
+
+示例 2:
+ ++输入:nums = [0,3,7,2,5,8,4,6,0,1] +输出:9 ++ +
+ +
提示:
+ +-
+
0 <= nums.length <= 105
+ -109 <= nums[i] <= 109
+
以下错误的选项是?
+ +## aop +### before +```cpp +#includem x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
++ +
示例 1:
+ +
++输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]] +输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]] +解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的+ +'O'都不会被填充为'X'。 任何不在边界上,或不与边界上的'O'相连的'O'最终都会被填充为'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。 +
示例 2:
+ ++输入:board = [["X"]] +输出:[["X"]] ++ +
+ +
提示:
+ +-
+
m == board.length
+ n == board[i].length
+ 1 <= m, n <= 200
+ board[i][j]为'X'或'O'
+
m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
++ +
示例 1:
+
++输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]] +输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]] +解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的+ +'O'都不会被填充为'X'。 任何不在边界上,或不与边界上的'O'相连的'O'最终都会被填充为'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。 +
示例 2:
+ ++输入:board = [["X"]] +输出:[["X"]] ++ +
+ +
提示:
+ +-
+
m == board.length
+ n == board[i].length
+ 1 <= m, n <= 200
+ board[i][j]为'X'或'O'
+
以下错误的选项是?
+ +## aop +### before +```cpp +#include给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。
叶子节点 是指没有子节点的节点。
+ ++ +
示例 1:
+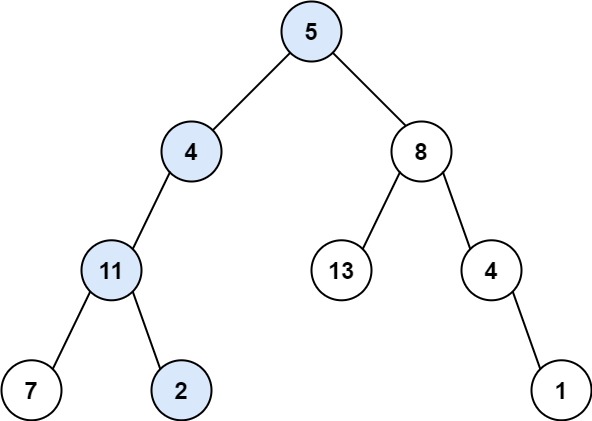 +
++输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22 +输出:true ++ +
示例 2:
+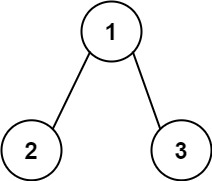 +
++输入:root = [1,2,3], targetSum = 5 +输出:false ++ +
示例 3:
+ ++输入:root = [1,2], targetSum = 0 +输出:false ++ +
+ +
提示:
+ +-
+
- 树中节点的数目在范围
[0, 5000]内
+ -1000 <= Node.val <= 1000
+ -1000 <= targetSum <= 1000
+
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。
叶子节点 是指没有子节点的节点。
+ ++ +
示例 1:
+
++输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22 +输出:true ++ +
示例 2:
+
++输入:root = [1,2,3], targetSum = 5 +输出:false ++ +
示例 3:
+ ++输入:root = [1,2], targetSum = 0 +输出:false ++ +
+ +
提示:
+ +-
+
- 树中节点的数目在范围
[0, 5000]内
+ -1000 <= Node.val <= 1000
+ -1000 <= targetSum <= 1000
+
以下错误的选项是?
+ +## aop +### before +```cpp +#include给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
+ ++ +
示例 1:
+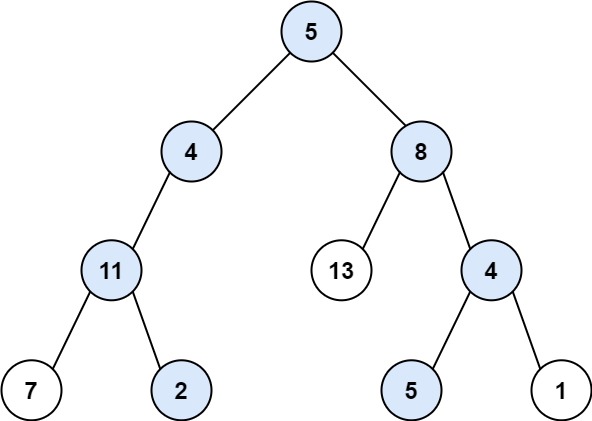 +
++输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22 +输出:[[5,4,11,2],[5,8,4,5]] ++ +
示例 2:
+
++输入:root = [1,2,3], targetSum = 5 +输出:[] ++ +
示例 3:
+ ++输入:root = [1,2], targetSum = 0 +输出:[] ++ +
+ +
提示:
+ +-
+
- 树中节点总数在范围
[0, 5000]内
+ -1000 <= Node.val <= 1000
+ -1000 <= targetSum <= 1000
+
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
+ ++ +
示例 1:
+
++输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22 +输出:[[5,4,11,2],[5,8,4,5]] ++ +
示例 2:
+
++输入:root = [1,2,3], targetSum = 5 +输出:[] ++ +
示例 3:
+ ++输入:root = [1,2], targetSum = 0 +输出:[] ++ +
+ +
提示:
+ +-
+
- 树中节点总数在范围
[0, 5000]内
+ -1000 <= Node.val <= 1000
+ -1000 <= targetSum <= 1000
+
以下错误的选项是?
+ +## aop +### before +```cpp +#includeBSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
+-
+
BSTIterator(TreeNode root)初始化BSTIterator类的一个对象。BST 的根节点root会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。
+ boolean hasNext()如果向指针右侧遍历存在数字,则返回true;否则返回false。
+ int next()将指针向右移动,然后返回指针处的数字。
+
注意,指针初始化为一个不存在于 BST 中的数字,所以对 next() 的首次调用将返回 BST 中的最小元素。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 的中序遍历中至少存在一个下一个数字。
+ +
示例:
+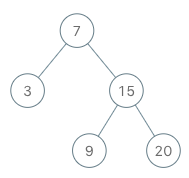 +
++输入 +["BSTIterator", "next", "next", "hasNext", "next", "hasNext", "next", "hasNext", "next", "hasNext"] +[[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []] +输出 +[null, 3, 7, true, 9, true, 15, true, 20, false] + +解释 +BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]); +bSTIterator.next(); // 返回 3 +bSTIterator.next(); // 返回 7 +bSTIterator.hasNext(); // 返回 True +bSTIterator.next(); // 返回 9 +bSTIterator.hasNext(); // 返回 True +bSTIterator.next(); // 返回 15 +bSTIterator.hasNext(); // 返回 True +bSTIterator.next(); // 返回 20 +bSTIterator.hasNext(); // 返回 False ++ +
+ +
提示:
+ +-
+
- 树中节点的数目在范围
[1, 105]内
+ 0 <= Node.val <= 106
+ - 最多调用
105次hasNext和next操作
+
+ +
进阶:
+ +-
+
- 你可以设计一个满足下述条件的解决方案吗?
next()和hasNext()操作均摊时间复杂度为O(1),并使用O(h)内存。其中h是树的高度。
+
BSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
+-
+
BSTIterator(TreeNode root)初始化BSTIterator类的一个对象。BST 的根节点root会作为构造函数的一部分给出。指针应初始化为一个不存在于 BST 中的数字,且该数字小于 BST 中的任何元素。
+ boolean hasNext()如果向指针右侧遍历存在数字,则返回true;否则返回false。
+ int next()将指针向右移动,然后返回指针处的数字。
+
注意,指针初始化为一个不存在于 BST 中的数字,所以对 next() 的首次调用将返回 BST 中的最小元素。
你可以假设 next() 调用总是有效的,也就是说,当调用 next() 时,BST 的中序遍历中至少存在一个下一个数字。
+ +
示例:
+
++输入 +["BSTIterator", "next", "next", "hasNext", "next", "hasNext", "next", "hasNext", "next", "hasNext"] +[[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []] +输出 +[null, 3, 7, true, 9, true, 15, true, 20, false] + +解释 +BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]); +bSTIterator.next(); // 返回 3 +bSTIterator.next(); // 返回 7 +bSTIterator.hasNext(); // 返回 True +bSTIterator.next(); // 返回 9 +bSTIterator.hasNext(); // 返回 True +bSTIterator.next(); // 返回 15 +bSTIterator.hasNext(); // 返回 True +bSTIterator.next(); // 返回 20 +bSTIterator.hasNext(); // 返回 False ++ +
+ +
提示:
+ +-
+
- 树中节点的数目在范围
[1, 105]内
+ 0 <= Node.val <= 106
+ - 最多调用
105次hasNext和next操作
+
+ +
进阶:
+ +-
+
- 你可以设计一个满足下述条件的解决方案吗?
next()和hasNext()操作均摊时间复杂度为O(1),并使用O(h)内存。其中h是树的高度。
+
以下错误的选项是?
+ +## aop +### before +```cpp +#includeTrie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
+ +请你实现 Trie 类:
+ +-
+
Trie()初始化前缀树对象。
+ void insert(String word)向前缀树中插入字符串word。
+ boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。
+ boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
+
+ +
示例:
+ +
+输入
+["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
+[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
+输出
+[null, null, true, false, true, null, true]
+
+解释
+Trie trie = new Trie();
+trie.insert("apple");
+trie.search("apple"); // 返回 True
+trie.search("app"); // 返回 False
+trie.startsWith("app"); // 返回 True
+trie.insert("app");
+trie.search("app"); // 返回 True
+
+
++ +
提示:
+ +-
+
1 <= word.length, prefix.length <= 2000
+ word和prefix仅由小写英文字母组成
+ insert、search和startsWith调用次数 总计 不超过3 * 104次
+
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
+ +请你实现 Trie 类:
+ +-
+
Trie()初始化前缀树对象。
+ void insert(String word)向前缀树中插入字符串word。
+ boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。
+ boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
+
+ +
示例:
+ +
+输入
+["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
+[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
+输出
+[null, null, true, false, true, null, true]
+
+解释
+Trie trie = new Trie();
+trie.insert("apple");
+trie.search("apple"); // 返回 True
+trie.search("app"); // 返回 False
+trie.startsWith("app"); // 返回 True
+trie.insert("app");
+trie.search("app"); // 返回 True
+
+
++ +
提示:
+ +-
+
1 <= word.length, prefix.length <= 2000
+ word和prefix仅由小写英文字母组成
+ insert、search和startsWith调用次数 总计 不超过3 * 104次
+
以下错误的选项是?
+ +## aop +### before +```cpp +#includeTinyURL是一种URL简化服务, 比如:当你输入一个URL https://leetcode.com/problems/design-tinyurl 时,它将返回一个简化的URL http://tinyurl.com/4e9iAk.
要求:设计一个 TinyURL 的加密 encode 和解密 decode 的方法。你的加密和解密算法如何设计和运作是没有限制的,你只需要保证一个URL可以被加密成一个TinyURL,并且这个TinyURL可以用解密方法恢复成原本的URL。
TinyURL是一种URL简化服务, 比如:当你输入一个URL https://leetcode.com/problems/design-tinyurl 时,它将返回一个简化的URL http://tinyurl.com/4e9iAk.
要求:设计一个 TinyURL 的加密 encode 和解密 decode 的方法。你的加密和解密算法如何设计和运作是没有限制的,你只需要保证一个URL可以被加密成一个TinyURL,并且这个TinyURL可以用解密方法恢复成原本的URL。
以下错误的选项是?
+ +## aop +### before +```cpp +#include给定一个已排序的正整数数组 nums,和一个正整数 n 。从 [1, n] 区间内选取任意个数字补充到 nums 中,使得 [1, n] 区间内的任何数字都可以用 nums 中某几个数字的和来表示。请输出满足上述要求的最少需要补充的数字个数。
示例 1:
+ +输入: nums =+ +[1,3], n =6+输出: 1 +解释: +根据 nums 里现有的组合[1], [3], [1,3],可以得出1, 3, 4。 +现在如果我们将2添加到 nums 中, 组合变为:[1], [2], [3], [1,3], [2,3], [1,2,3]。 +其和可以表示数字1, 2, 3, 4, 5, 6,能够覆盖[1, 6]区间里所有的数。 +所以我们最少需要添加一个数字。
示例 2:
+ +输入: nums =+ +[1,5,10], n =20+输出: 2 +解释: 我们需要添加[2, 4]。 +
示例 3:
+ +输入: nums =diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/10.330-\346\214\211\350\246\201\346\261\202\350\241\245\351\275\220\346\225\260\347\273\204/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/10.330-\346\214\211\350\246\201\346\261\202\350\241\245\351\275\220\346\225\260\347\273\204/solution.cpp" new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/10.330-\346\214\211\350\246\201\346\261\202\350\241\245\351\275\220\346\225\260\347\273\204/solution.json" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/10.330-\346\214\211\350\246\201\346\261\202\350\241\245\351\275\220\346\225\260\347\273\204/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..45a439702f4f31572ec68806de1270d79b3082ae --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/10.330-\346\214\211\350\246\201\346\261\202\350\241\245\351\275\220\346\225\260\347\273\204/solution.json" @@ -0,0 +1,6 @@ +{ + "type": "code_options", + "author": "CSDN.net", + "source": "solution.md", + "exercise_id": "f2e948669b074e0894d025effeeddcb7" +} \ No newline at end of file diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/10.330-\346\214\211\350\246\201\346\261\202\350\241\245\351\275\220\346\225\260\347\273\204/solution.md" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/10.330-\346\214\211\350\246\201\346\261\202\350\241\245\351\275\220\346\225\260\347\273\204/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..693080f4cff6bcf2865faddd204569c9fbe38f7b --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/10.330-\346\214\211\350\246\201\346\261\202\350\241\245\351\275\220\346\225\260\347\273\204/solution.md" @@ -0,0 +1,172 @@ +# 按要求补齐数组 +[1,2,2], n =5+输出: 0 +
给定一个已排序的正整数数组 nums,和一个正整数 n 。从 [1, n] 区间内选取任意个数字补充到 nums 中,使得 [1, n] 区间内的任何数字都可以用 nums 中某几个数字的和来表示。请输出满足上述要求的最少需要补充的数字个数。
示例 1:
+ +输入: nums =+ +[1,3], n =6+输出: 1 +解释: +根据 nums 里现有的组合[1], [3], [1,3],可以得出1, 3, 4。 +现在如果我们将2添加到 nums 中, 组合变为:[1], [2], [3], [1,3], [2,3], [1,2,3]。 +其和可以表示数字1, 2, 3, 4, 5, 6,能够覆盖[1, 6]区间里所有的数。 +所以我们最少需要添加一个数字。
示例 2:
+ +输入: nums =+ +[1,5,10], n =20+输出: 2 +解释: 我们需要添加[2, 4]。 +
示例 3:
+ +输入: nums =+ +[1,2,2], n =5+输出: 0 +
以下错误的选项是?
+ +## aop +### before +```cpp +#include给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。
注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。
+ ++ +
示例 1:
+ ++输入+ +:nums = [10,2]+输出:"210"
示例 2:
+ ++输入+ +:nums = [3,30,34,5,9]+输出:"9534330"+
示例 3:
+ +
+输入:nums = [1]
+输出:"1"
+
+
+示例 4:
+ +
+输入:nums = [10]
+输出:"10"
+
+
++ +
提示:
+ +-
+
1 <= nums.length <= 100
+ 0 <= nums[i] <= 109
+
给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。
注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。
+ ++ +
示例 1:
+ ++输入+ +:nums = [10,2]+输出:"210"
示例 2:
+ ++输入+ +:nums = [3,30,34,5,9]+输出:"9534330"+
示例 3:
+ +
+输入:nums = [1]
+输出:"1"
+
+
+示例 4:
+ +
+输入:nums = [10]
+输出:"10"
+
+
++ +
提示:
+ +-
+
1 <= nums.length <= 100
+ 0 <= nums[i] <= 109
+
以下错误的选项是?
+ +## aop +### before +```cpp +#include给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
注意:该题与 1081 https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters 相同
+ ++ +
示例 1:
+ ++输入:+ +s = "bcabc"+输出:"abc"+
示例 2:
+ ++输入:+ +s = "cbacdcbc"+输出:"acdb"
+ +
提示:
+ +-
+
1 <= s.length <= 104
+ s由小写英文字母组成
+
给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
注意:该题与 1081 https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters 相同
+ ++ +
示例 1:
+ ++输入:+ +s = "bcabc"+输出:"abc"+
示例 2:
+ ++输入:+ +s = "cbacdcbc"+输出:"acdb"
+ +
提示:
+ +-
+
1 <= s.length <= 104
+ s由小写英文字母组成
+
以下错误的选项是?
+ +## aop +### before +```cpp +#include给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
+ +示例 1:
+ +输入: +nums1 =+ +[3, 4, 6, 5]+nums2 =[9, 1, 2, 5, 8, 3]+k =5+输出: +[9, 8, 6, 5, 3]
示例 2:
+ +输入: +nums1 =+ +[6, 7]+nums2 =[6, 0, 4]+k =5+输出: +[6, 7, 6, 0, 4]
示例 3:
+ +输入: +nums1 =diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/9.321-\346\213\274\346\216\245\346\234\200\345\244\247\346\225\260/solution.cpp" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/9.321-\346\213\274\346\216\245\346\234\200\345\244\247\346\225\260/solution.cpp" new file mode 100644 index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/9.321-\346\213\274\346\216\245\346\234\200\345\244\247\346\225\260/solution.json" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/9.321-\346\213\274\346\216\245\346\234\200\345\244\247\346\225\260/solution.json" new file mode 100644 index 0000000000000000000000000000000000000000..c261539a8b2c0ca7162c328c5888348bf60f01b3 --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/9.321-\346\213\274\346\216\245\346\234\200\345\244\247\346\225\260/solution.json" @@ -0,0 +1,6 @@ +{ + "type": "code_options", + "author": "CSDN.net", + "source": "solution.md", + "exercise_id": "d4bef81d1bd84c0db36d6488b1932479" +} \ No newline at end of file diff --git "a/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/9.321-\346\213\274\346\216\245\346\234\200\345\244\247\346\225\260/solution.md" "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/9.321-\346\213\274\346\216\245\346\234\200\345\244\247\346\225\260/solution.md" new file mode 100644 index 0000000000000000000000000000000000000000..3728fb4b86838a2f89602ac97a6b5dd89e4cf08d --- /dev/null +++ "b/data/3.\347\256\227\346\263\225\351\253\230\351\230\266/8.leetcode-\350\264\252\345\277\203/9.321-\346\213\274\346\216\245\346\234\200\345\244\247\346\225\260/solution.md" @@ -0,0 +1,333 @@ +# 拼接最大数 +[3, 9]+nums2 =[8, 9]+k =3+输出: +[9, 8, 9]
给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
+ +示例 1:
+ +输入: +nums1 =+ +[3, 4, 6, 5]+nums2 =[9, 1, 2, 5, 8, 3]+k =5+输出: +[9, 8, 6, 5, 3]
示例 2:
+ +输入: +nums1 =+ +[6, 7]+nums2 =[6, 0, 4]+k =5+输出: +[6, 7, 6, 0, 4]
示例 3:
+ +输入: +nums1 =+ +[3, 9]+nums2 =[8, 9]+k =3+输出: +[9, 8, 9]
以下错误的选项是?
+ +## aop +### before +```cpp +#include