- 博客(106)
- 收藏
- 关注
 RSS订阅
RSS订阅
原创 Spring-Smart-DI 动态切换实现类
传统的快速切换逻辑实现方法是,先为每个服务商编写对应的实现类,然后在配置点(这个配置点可以是数据库,也可以是像 Nacos 这样的配置中心)配置当前正在使用的服务商。其一,为了规避某个服务商的服务出现不可用的风险,以便在出现问题时能够迅速切换到其他服务商,确保系统的稳定性和业务的连续性;注解在注入时能够自动根据配置点的配置去注入对应的实现类,并且当配置发生变化时,注入的实现类也能自动更新呢?通过以上的步骤,我们就可以灵活地实现动态切换服务提供商的功能,并且可以根据不同的需求自定义配置获取逻辑。
2025-03-17 11:36:13
 501
501
原创 Flink和Spark在流处理上的区别
若场景以批处理为主(如离线数据分析、机器学习),或需兼容现有 Hadoop 生态(如 Hive、HDFS),且对流处理的延迟要求不高(秒级)。若需毫秒级实时处理(如金融风控、IoT 传感器分析),或需灵活的状态管理、复杂事件处理(CEP)。两者未来趋势呈现融合,如 Spark 逐步优化流处理(如 Continuous Processing 模式),而 Flink 扩展批处理能力,最终可能形成互补共存的生态。
2025-03-04 10:58:23
1266
原创 什么是Spark?
Spark 是大数据领域的“瑞士军刀”,能高效解决批处理、实时流、机器学习、图计算等多种问题。凭借其速度优势和丰富的生态系统,已成为企业处理复杂数据任务的标配工具。如果项目需要快速处理海量数据,并兼顾灵活性和易用性,Spark 是理想选择。
2025-03-04 10:25:24
471
原创 DeepSeek之Api的使用(将DeepSeek的api集成到程序中)
使用DeepSeek的api是收费的免费版:可能提供有限的免费额度(如每月一定次数的 API 调用),适合个人开发者或小规模项目。付费版:超出免费额度后,可能需要按调用次数、数据量或订阅计划收费。企业版:针对企业用户,可能提供定制化服务和更高的调用限额,通常需要联系销售团队获取报价。
2025-02-09 21:40:52
1861
原创 我的创作纪念日
提示:你过去写得最好的一段代码是什么?提示:当前创作和你的工作、学习是什么样的关系。提示:可以和大家分享最初成为创作者的初心。提示:在创作的过程中都有哪些收获。提示:职业规划、创作规划等。
2025-05-08 09:15:56
217
原创 什么是高并发与多线程?
线程 是程序执行的最小单元,是进程中的一个独立执行路径。一个进程可以包含多个线程,这些线程共享进程的资源(如内存、文件句柄等),但每个线程有自己的栈和程序计数器。多线程是 Java 编程中的一个重要特性,它允许程序同时执行多个任务,从而提高程序的效率和性能。Java 提供了丰富的 API 来支持多线程编程,包括 Thread 类、Runnable 接口、Executor 框架、MultiFutureThread等。优点是提高程序的效率、缺点是比较消耗CPU和内存。
2025-04-02 11:04:22
560
原创 SpringBoot之一个注解完成所有类型的文件下载!
通过在 Device 的字段上标注某些注解(或是实现某个接口)来指定文件名称和文件地址如果能这样实现,省时省心省力,又多了写 199 行代码的摸鱼时间难道不香么。对于简单的下载,是不是简单多了?那么对于复杂的下载考虑的问题多,代码实现也相对复杂,那么使用这个注解会更加的凸显便利!下载功能应该是比较常见的功能了,每个项目里都会有,简单的下载不难但是代码多也麻烦,对于复杂的下载代码更多更是麻烦。:我们有一个平台是管理生活用品的,然后每个生活用品都会有一个二维码图片,用一个字段存储的 http 地址。
2025-03-17 10:51:14
290
原创 Fink与Hadoop的简介以及联系
Fink 和 Hadoop 可以互补使用,Fink 负责实时数据处理,Hadoop 负责批处理和存储。通过集成,能够构建一个既能实时处理又能进行大规模离线分析的系统,满足多样化的数据处理需求。
2025-02-17 13:09:25
625
原创 AtomicLong、ConcurrentHashMap、AtomicReference在多线程MultiFutureThread下的应用
AtomicLong、ConcurrentHashMap、AtomicReference类。在多线程MultiFutureThread开发中,为了确保数据的正确 需要使用。其中AtomicReference可以封装List以及java对象。
2024-12-05 10:14:29
113
原创 mysql使用JSON_OBJECT对json格式的字段进行精确匹配
【代码】mysql使用JSON_OBJECT对json格式的字段进行精确匹配。
2024-11-20 09:41:47
153
原创 ClickHouse之更新表(ReplicatedReplacingMergeTree)
但是,只有MergeTree系列的表引擎才支持主键索引,数据分区,数据副本,数据采样这样的特性,只有此系列的表引擎才支持alter操作。PARTITION BY:指定分区键,主要根据你的业务场景和数据量大小,可以按年、按月、按天或者其他时间间隔分区,也可以按照哈希去分区。index_granularity:默认8192,表示索引的粒度,即MergeTree的索引在默认情况下,每间隔8192行才生成一个索引。但是,如果同一order key散落到了不同的分区、不同的分片中,去重会失效;CK会自动取最新的;
2024-10-09 10:02:12
946
原创 Clickhouse之更新表(ReplacingMergeTree)
注意:ReplacingMergeTree在建表时可以看到ENGINE = ReplacingMergeTree(ts),其中的ts就是版本信息,clickhouse会每次插入记录版本,就是依据这个字段,在查询时会返回最后最新的版本数据。所以第二个insert的ts和第一个insert的ts字段的值一样,所以会以第二条记录为准,即实现了更新。这种方式就不用执行alter了,而是以insert的形式来代替alter操作,即每次select时都是取最新的一条数据,sql语句如下。
2024-10-09 09:20:24
827
原创 SpringBoot + 虚拟线程,性能炸裂!
虚拟线程是Java19开始增加的一个特性,和Golang的携程类似,一个其它语言早就提供的、且如此实用且好用的功能,作为一个Java开发者,早就已经望眼欲穿了。
2024-07-02 17:59:13
438
原创 一个强大的分布式锁框架——Lock4j
Lock4j是一个分布式锁组件,它提供了多种不同的支持以满足不同性能和环境的需求,基于Spring AOP的声明式和编程式分布式锁,支持RedisTemplate、Redisson、Zookeeper。```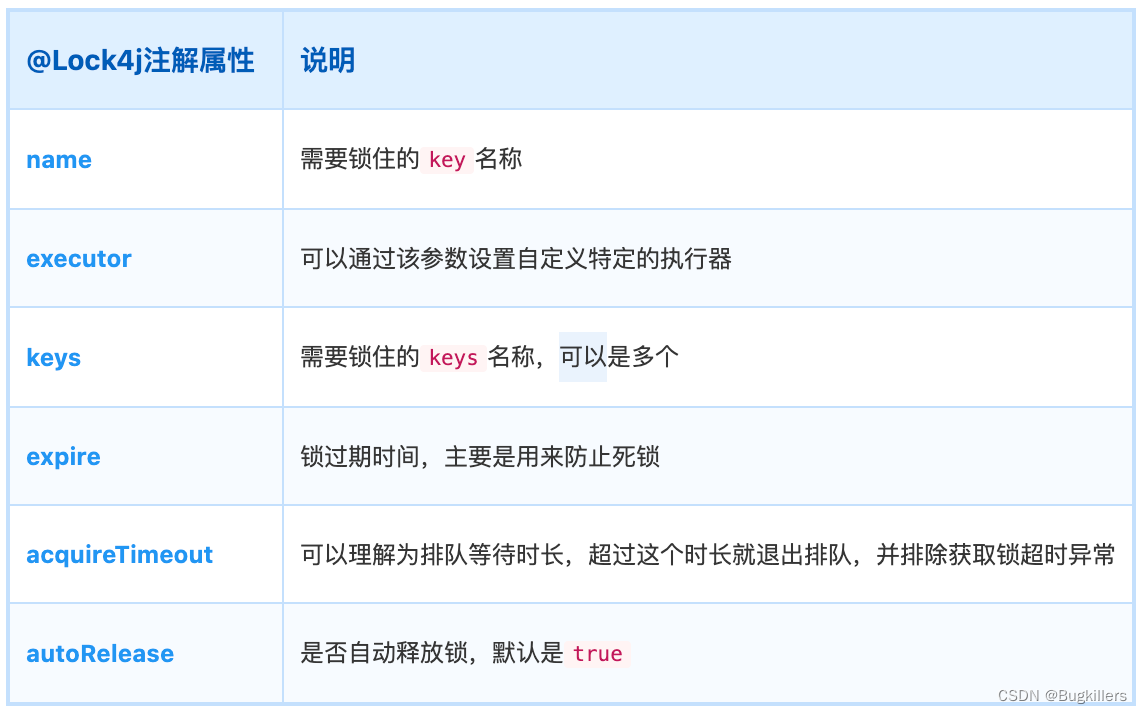### 五、简单使用```java。
2024-07-02 11:23:46
545
原创 TCP和Udp的区别是什么?
TCP 的数据大小如果大于 MSS 大小,则会在传输层进行分片,目标主机收到后,也同样在传输层组装 TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。UDP 的数据大小如果大于 MTU 大小,则会在 IP 层进行分片,目标主机收到后,在 IP 层组装完数据,接着再传给传输层。由于 UDP 面向无连接,它可以随时发送数据,再加上UDP本身的处理既简单又高效,因此经常用于:包总量较少的通信,如 DNS 、SNMP 等;UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
2024-05-24 17:18:23
242
原创 什么是ClickHouse?如何使用
clickhouse数据库是大型分布式数据存储系统,由于其独特的数据存储方式(基于列式存储)以及数据存储在磁盘中(数据会被压缩),使cluckhouse的数据读取和存储速度很快。
2024-05-13 09:46:19
430
 1
1
原创 java多线程实战1:方法内部使用多线程的两种方式
我们在开发过程中,有时会遇到一个方法内去循环执行某个任务,而每次循环执行的这个任务会耗时很大,如果循环次数又比较多的话,那么总体下来这个方式执行的时间会很长。如何解决这个问题,可以在很快的时间内完成这个方法?这个时候就要用到线程池了,使用线程池异步执行任务。
2023-12-22 11:36:12
604
原创 TensorFlow是什么
图:TensorFlow将计算表达为一个数据流图,图中的节点表示算法的操作,边表示节点之间的数据流动。在图中,节点分为两种类型:计算节点和变量节点,计算节点用于执行各种计算操作,变量节点用于存储和更新模型参数。总之,TensorFlow是一个功能强大的深度学习框架,可以用于各种机器学习任务,包括图像识别、自然语言处理、推荐系统和数据分析等。会话可以在本地机器上执行,也可以在分布式集群上执行。张量:TensorFlow使用张量表示所有的数据,张量可以是任意维度和类型的数据,例如标量、向量、矩阵等。
2023-09-04 17:00:31
952
1
原创 mysql表锁死怎么办?事务锁sql超时被锁死怎么办?
1、查询所有进程:SHOW PROCESSLIST;2、找到进程号kill掉kill 32699871、查询所有执行中的sqlselect t.*,to_seconds(now())-to_seconds(t.trx_started) idle_time from INFORMATION_SCHEMA.INNODB_TRX t2、找到状态为lock的sql的trx_mysql_thread_id并kill掉kill 32699878
2023-08-25 09:24:45
1053
原创 kafka数据积压原因以及解决方案
首先我们在上面分析得出,是由于上游生产者producer发送数据过快,以及下游消费者consumer拉取数据过慢,实质上就是,生产者生产数据速度>>消费者消费数据速度。我们都知道,数据积压的直接原因,一定是系统中的某个部分出现了性能问题,来不及处理上游发送的数据,才会导致数据积压。那么我们就需要分析在使用kafka时,如何通过优化代码以及参数配置来最大程度的避免数据积压来对业务中的影响。数据积压可能是我们在编写代码处理逻辑的时候,代码质量不高,处理速度慢导致消费数据的性能低,可以优化代码。
2023-07-14 11:25:36
3607
原创 数据安全:数据库密码的加解密
我们在使用一些数据库或者其他连接工具的时候,为了保证数据安全性,希望对数据库等访问工具的密码进行加解密,比如MySQL、es、kafka等。
2023-05-08 10:47:59
1274
原创 定时频繁的查询es导致Too many open files 与 java.lang.OutOfMemoryError
出现这种问题是因为打开过多的句柄(或者请求链接),超出系统设定的句柄数。我这里是因为系统定时的去调用接口,由于使用线程池并发调用接口次数过多,导致超出系统设定的请求链接次数。上面的问题是句柄数不够,这个出现这种问题的原因是内存不足的造成的,可以从代码优化,以及系统调优两个方面解决。最好的是优化代码,实在不行再去系统调优。3、永久生效(需要重启)1、查看句柄限制数量。
2023-04-18 09:31:45
632
原创 超详细Linus安装maven、配置maven环境
修改settings.xml文件。如果安装了maven,删除掉。添加本地仓库地址与阿里云镜像。创建maven仓库文件夹。
2023-04-12 11:37:49
1294
原创 浅说java的xml中的foreach用法
三、当mapper中的参数是多个,都需要绑定@Param注解,此时xml中collection的值是绑定注解的参数(无论参数是数组还是集合)如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array。如果传入的是单参数且参数类型是一个List的时候,collection属性值为list。在使用foreach的时候最关键的也是最容易出错的就是collection属性,该属性是必须指定的,但是在不同情况 下,该属性的值是不一样的,item :表示集合中的每一个元素。
2023-04-04 11:22:13
2295
原创 windows系统下的maven打包脚本
编写windows系统下的maven打包脚本:新建文本文件,后缀改为bat,将以下内容复制到文件中,将脚本文件放在需要打包的模块并列的目录中,双击运行脚本即可。需事先配置好maven环境变量M2_HOME为maven根目录。
2023-02-04 09:24:54
762
原创 UNION与UNION ALL的区别
原始数据:UNION ALL 行转列后:区别:1.对重复结果的处理:UNION会去掉重复记录,UNION ALL不会2.对排序的处理:UNION会排序,UNION ALL只是简单地将两个结果集合并3.效率方面的区别:因为UNION 会做去重和排序处理,因此效率比UNION ALL慢很多...
2022-06-08 10:28:52
914
原创 MYSQL行转列与列转行
±-----±-----+| id| name |±-----±-----+|1 | 10||1 | 20||1 | 20||2 | 20||3 | 200 ||3 | 500 |±-----±-----+6 rows in set (0.00 sec)1.以id分组,把name字段的值打印在一行,逗号分隔(默认)±-----±-------------------+| id| group_concat(name) |±-----±-------------------+|1 |
2022-06-08 09:55:18
607
原创 java集合排序
1.List<RiskUserInfoVo > vos= userInfoList.sort(new Comparator<RiskUserInfoVo>() { @Override public int compare(RiskUserInfoVo o1, RiskUserInfoVo o2) { return o2.getSeriousValue().compareTo(o1.getSeriousVa
2022-05-30 17:19:05
129
原创 统计任意时间段、近一天、近一周、近一月、近一年(12个月)的数据(折线图、柱形图、扇形图)
一、前端会传统计类型type(1,2,3),比如近一周、近一月、近一年(12个月),我们先根据type生成日期集合,这将作为X轴: List<String> xData = selectDate(type,startDate,endDate); private List<String> selectDate(String type,String startDate,String endDate){ if ("1".equals(type)){
2022-05-19 14:40:46
2372
原创 Spring拦截器整合token
https://blog.csdn.net/fuckthebugs/article/details/105775579
2022-03-18 11:20:55
230
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人