- 博客(89)
- 资源 (3)
- 收藏
- 关注
 RSS订阅
RSS订阅原创 (数字ic)CDC设计实例 - ICG :integrate Clock Gating Cell
CDC设计实例 - ICG :integrate Clock Gating Cell1、Latch原理2、ICG消除毛刺原理1)en信号中的毛刺出现在clk低电平期间,如下图所示2)en信号出现在clk高电平期间,如下图所示3、SoC系统中时钟切换应用场景1、Latch原理锁存器(latch):所谓锁存器,就是输出端的状态不会随输入端的状态变化而变化,仅在有锁存信号时输入的状态才被保存到输出,直到下一个锁存信号到来时才改变。2、ICG消除毛刺原理Clock gating cell 可以由与门或者或门
2022-05-10 11:31:25
 4085
4085
 1
1
原创 (数字ic)CDC跨时钟域可能出现的问题及解决办法总结
1、CDC基本概念时钟域(Clock Domain):时钟域为由单个时钟或具有恒定相位关系的时钟驱动的设计部分。换句话说,时钟域就是时钟信号的势力范围且一个时钟域中只能存在一个时钟信号,而一个时钟信号最多可以对应两个时钟域。多个时钟来自不同的来源,而由这些时钟驱动的逻辑单元部分为时钟域,这些异步时钟域之间的接口信号称为时钟域交叉(CDC)路径。如图一,divCLK是由CLK分频得到的,所以divCLK和CLK为同步时钟,也是属于同一个时钟域的。...
2022-05-09 10:21:04
5107
1
原创 (tensorflow2.1.0安装教程) 对应Anaconda3(对应python3.7)+cuda10.1+cudnn7.6.5+Pycharm 网盘 链接
tensorflow2.1.0 安装工具百度网盘链接整体安装流程及版本:Anaconda3(2019)对应python3.7+cuda10.1+cudnn7.6.5+Pycharm第一步: 首先确保电脑上原先所有的python和conda环境卸载干净网盘获取:<1>Anaconda3-5.3.1-Windows-x86_64.exe链接:https://pan.baidu.com/s/1mMOVgFkCfhF6hYTGdEGJKQ提取码:2zk8<2 >cuda_1
2022-01-25 21:41:06
1960
1
原创 (FPGA) IP核之PLL
FPGA - IP核之PLL1. PLL IP核简介2. 实验任务3. 硬件设计4. 程序设计5. 下载验证1. PLL IP核简介PLL的结构图如下:PLL由以下几部分组成:前置分频计数器(N计数器)、相位-频率检测器(PFD,Phase-Frequency Detector)电路电荷泵(Charge Pump)环路滤波器(Loop Filter)、压控振荡器(VCO,Voltage Controlled Oscillator)反馈乘法器计数器(M计数器)后置分频计数器(K和V计数器
2022-01-05 16:50:55
2259
原创 (计算机网络)计算机网络面试题总结 校招
计算机网络面试题总结网络分层问题一:OSI七层模型和TCP/IP五层模型各层的作用?问题二:交换机、路由器、网关的概念,并知道各自的用途?各层的协议应用层:问题一:理解域名解析系统DNS?问题二:域名解析过程?问题三:理解超文本传输协议HTTP?问题四:理解文件传送协议FTP?问题五:理解电子邮件系统协议SMTP/POP3/IMAP?问题六:理解动态主机配置协议DHCP?问题七:理解简单网络管理协议SNMP?传输层:问题一:传输控制协议TCP和用户数据报协议UDP的特点和区别?问题二:TCP协议如何保证可靠
2021-08-25 19:09:01
1097
原创 数据结构和算法
数据结构和算法一、数据结构和算法概述1.1 什么是数据结构?1.2 数据结构分类1.2.1 逻辑结构1.2.2 物理结构1.3 算法概述1.4 算法初体验二、算法一、数据结构和算法概述1.1 什么是数据结构?官方解释:数据结构是一门研究非数值计算的程序设计问题中的操作对象,以及他们之间的关系和操作等相关问题的学科。大白话:数据结构就是把数据元素按照一定的关系组织起来的集合,用来组织和存储数据1.2 数据结构分类传统上,我们可以把数据结构分为逻辑结构和物理结构两大类。1.2.1 逻辑结构逻
2021-07-03 21:30:11
324
2
原创 数据仓库分层 (ODS、DWD、DWS)
数据仓库分层1.数据仓库DW1.1简介1.2主要特点1.3与数据库的对比2.数据分层2.1数据运营层(ODS)2.2数据仓库层(DW)2.3数据服务层/应用层(ADS)3.附录数据库设计三范式作者:AmyZYX 出处:http://www.cnblogs.com/amyzhu/1.数据仓库DW1.1简介Data warehouse(可简写为DW或者DWH)数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它是一整套包括了etl、调度、建模在内的完整的理论体系
2021-06-12 15:35:12
4693
原创 Kafka(消息中间件)
Kafka的原理一、消息中间件概述(MQ)二、消息中间件的组成三、消息中间件模式分类3.1 点对点3.2 发布/订阅3.3 queue和topic对比四、消息中间件的优势4.1 系统解耦4.2 提高系统响应时间4.3 为大数据处理架构提供服务4.4 Java消息服务——JMS五、消息中间件应用场景5.1 异步通信5.2 解耦5.3 减少冗余5.4 扩展性高5.5 过载保护5.6 可恢复性5.7 顺序保护5.8 缓冲5.9 数据流处理6 消息中间件常用协议6.1 AMQP协议6.2 MQTT协议6.3 STO
2021-06-06 21:13:08
1541
原创 Kafka(数据从Kafka导入到Hbase)
数据从Kafka导入到Hbase一、数据从Kafka导入到Hbase(1) 非面向对象写法(2) 面向对象(OOP)写法1)先将这一段写成接口,这里面的内容根据不同的表数据结构而不同,其余部分的代码都几乎是不用变化的2)将写入hbase部分写成接口形式(红色方框的部分)3)最后将kafka消费端属性配置写入接口二、提取接口遵循规则一、数据从Kafka导入到Hbase前面两篇博客是第一步和第二步操作(1)将数据通过flume导入kafka:(2)将导入kafka的数据通过kafka streamin
2021-06-06 21:04:57
3764
原创 Kafka-Streaming
Kafka Streaming一、流计算定义二、Kafka Streams2.1 概述2.2 kafka streams的优点2.3 Topology实例1:实例2:三、窗口3.1 Hopping time window3.1 Tumbling time window3.1 Session window一、流计算定义一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。
2021-06-06 21:04:29
896
原创 Flume(flume自带拦截器、自定义拦截器)
Flume自带拦截器、自定义拦截器一、Flume自带的拦截器二、自定义拦截器一、Flume自带的拦截器示例1:具体实现:通过正则表达式,过滤掉匹配上的消息,这里是以user开头的消息实现一个source传向2个通道,两个sink将两个通道的数据分别传入Kafka和hdfs配置文件:定义三个组件://agent组件的三部分的初始化定义train.sources=trainSourcetrain.channels=kafkaChannel hdfsChanneltrain.sinks=ka
2021-06-06 21:03:40
1440
原创 Kafka(单机安装配置、常用操作)
Kafka的单机安装配置、常用操作一、Kafka的单机安装二、kafka基本操作三、kafka — Java API一、Kafka的单机安装1、解压2、改名字mv kafka_2.11-2.0.0.tgz kafka2113、进入producer.properties,修改配置文件[root@hadoop2 kafka211]# vi ./config/producer.properties修改以下四个地方:先在 kafka211的路径下创建kafka211-logs文件夹,日
2021-06-06 21:02:44
524
原创 kafka(数据可靠性深度解读)
kafka 数据可靠性深度解读一、概述二、Kafka体系架构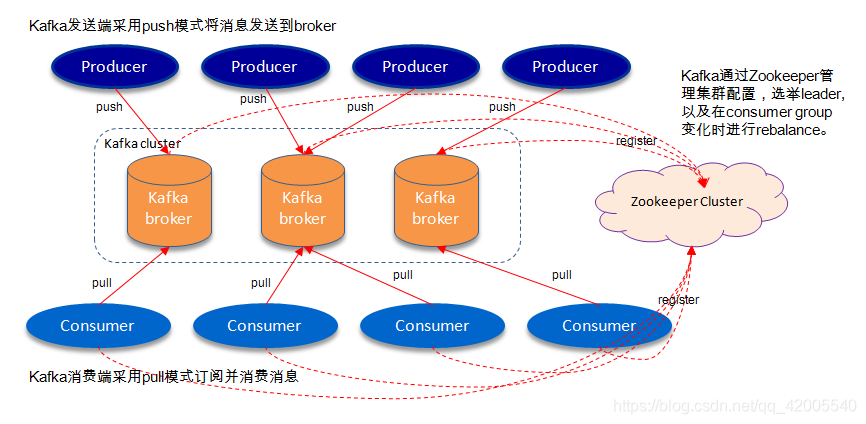2.1 Kafka架构中的主要角色2.2
2021-06-06 21:02:18
529
原创 JDK配置
JDK及IDEA安装JDK配置IDEA配置JDK配置以JDK1.8为例;需注意,jdk安装路径中不要包含中文;安装成功后,在DOS窗口执行java -version命令可弹出以下界面,说明安装成功;d:表示切换至D盘;cd 文件名表示进入该文件右键我的电脑,选择属性,依次点击高级系统设置-环境变量进入环境变量设置页面,需要对JAVA_HOME、CLASSPATH和Path三个属性进行配置在系统变量下方点击新建;JAVA_HOME(全大写);变量值为JDK安装目录(bin包的上一级);
2021-05-27 13:20:47
558
1
原创 Spark(RDD概念、Action、Transformation、练习题)
Spark(RDDS概念、Action、Transformation、练习题)一、RDD概念:(1) 弹性分布式数据集(RDD)(2) RDD两种操作的简单介绍二、RDD练习题:一、RDD概念:(1) 弹性分布式数据集(RDD)1.1 Spark是以RDD概念为中心运行的。RDD是一个容错的、可以被并行操作的元素集合。创建一个RDD有两个方法:在你的驱动程序中并行化一个已经存在的集合;从外部存储系统中引用一个数据集。RDD的一大特性是分布式存储,分布式存储在最大的好处是可以让数据在不同工作节点并行存
2021-05-07 22:49:28
988
2
原创 Scala(逆变协变、scala连接mysql数据库)
逆变协变、scala连接mysql数据库一、逆变协变二、`scala`连接`mysql`数据库一、逆变协变+B是B的超集,叫协变-A是A的子集,叫逆变object ObjCovariantAndInversionDmo { class Animal { def eat(): Unit = { println("动物吃东西") } } class Cat extends Animal { // 猫科动物 override def eat(): Uni
2021-04-27 20:46:19
249
原创 scala(偏函数、部分函数、模式匹配、面向对象oop)
这里写自定义目录标题一、偏函数二、部分函数三、模式匹配基本模式匹配匹配异常匹配字符串样例类四、Scala面向对象(1)类 (class)(2)抽象类 (abstract class) 和 特质(trait)(3)单例对象(object) ---伴生类 伴生对象(4)样例类(case class)一、偏函数偏函数是只对函数定义域的一个子集进行定义的函数PartialFunction[-A,+B]是一个特质A为函数定义域,B为偏函数返回值类型apply()isDefinedAt()偏函数,传入
2021-04-26 22:13:56
416
原创 scala函数
scala函数Scala函数定义一、参数传递例:定义一个没有返回值的函数,实现输入一个整数,打印金字塔。例:打印出空的倒三角形二、参数命名:三、参数缺省值四、匿名函数五、高阶函数六、嵌套函数七、柯里化(Currying)八、隐式参数九、隐式函数 -- 数据类型转换十、隐式类Scala函数定义函数是Scala的核心定义:def 函数名([参数列表]):[返回值]={函数图return[表达式]}一、参数传递传值调用(call-by-value)传值调用时,参数只在调用时计算一次,后续重复使
2021-04-24 18:19:46
841
原创 scala基础入门
scala基础入门一、数据类型分类二、字符串插值三、条件控制语句四、循环控制五、for 循环过滤六、中断七、 scala数组创建八、 scala创建元组一、数据类型分类Any:所有类型的超类(顶级类型)包含:AnyVal:值类型的超类 AnyRef引用类型的超类AnyVal:表示值类型的超类包含Double,Float,Int,Short,Long,Char,Byte,Unit,Boolean —NothingAnyRef:表示引用类型的超类,对应java.lang.Object包
2021-04-24 17:53:32
214
原创 阿里云上传、下载文件
第一步:在某个盘中建一个gidData文件夹(文件名随意)第二步:该文件夹中右击选择Git Bash Here第三步:克隆统一上传的git地址在命令行输入:git clone https://code.aliyun.com/xxxxx/testTMall.git第四步:在克隆的testTMall中创建文件夹,将需要上传的文件拖入文件夹,或直接将文件拖入testTMall中第五步:进入testTMall目录,将待上传的文件add到git上在命令行输入:git add 文件夹名第六步:提交文件在
2021-04-15 09:00:07
649
1
原创 使用JAVA API操作HBase
建立连接:TestConnimport org.apache.commons.configuration.ConfigurationFactory;import org.apache.hadoop.classification.InterfaceAudience;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.
2021-04-12 20:12:55
496
原创 Sqoop(sqoop的安装;sqoop概述;sqoop应用:关系型数据库导入HDFS、hive、hbase;从HDFS导出到mysql)
sqoop一、Sqoop的安装及配置二、关系型数据库导入HDFS2.1 将表从mysql导入到HDFS2.2 通过Where语句过滤导入表2.3 通过column过滤导入表2.4 使用query方式导入数据2.5 使用sqoop增量导入数据2.6 导入时指定输出文件格式2.7 导出HDFS数据到MySQL三、关系型数据库导入hive四、关系型数据库导入hbase一、Sqoop的安装及配置1、前提条件安装好:java、hadoop、hive、hbase、zookeeper的环境2、解压压缩包并改名
2021-04-12 19:01:16
433
原创 HBase基础(hbase安装配置、hbase概述、hbase生态圈、hbase基本操作)
HBase基础一、HBase的安装和配置二、HBase概述2.1 概述2.2 NoSql和关系型数据库的对比2.3 NoSql的特点三、HBase生态圈四、HBase物理架构五、HBase Shell的基本操作5.1 创建表 create5.2 查看所有表:list,describe5.3 添加数据:put5.4 扫描表:scan5.5 获取数据:get5.6 删除数据:delete5.7 修改表:alter5.8 删除表:drop一、HBase的安装和配置1、解压安装包到software文件夹下t
2021-04-08 16:13:42
827
原创 Hive基本内置函数、自定义函数以及性能优化
目录一、内置函数二、自定义函数2.1 自定义函数类型2.2 自定义函数步骤第一步:新建maven工程第二步:添加UDF函数开发的依赖包第三步:创建类,写java代码第四步:测试成功之后,打jar包,上传到`liunx`上第五步:添加jar包、创建函数(两种方式)一、内置函数略二、自定义函数2.1 自定义函数类型从输入输出角度分类标准函数一行数据中的一列或多列为输入,结果为单一值多行的零列到聚合函数多列为输入,结果为单一值表生成函数零个或多个输入,结果为多列或多
2021-04-06 18:59:11
399
原创 Hive知识点总结
Hive知识点总结一、启动Hive和zeppelin二、Hive和Mysql的主要区别三、hive中的数据类型1、基本数据类型2、复杂数据类型3、元数据结构四、内部表和外部表五、hive-创建表详细内容见上一篇博客:[建表语句](https://blog.csdn.net/qq_42005540/article/details/115307983)补充:Hive建表–Storage SerDe六、hive-分区和分桶6.1 分区创建分区插入数据6.2 设置动态分区6.3 分桶第一步:设置分桶数量第二步:创建
2021-04-05 21:57:41
807
原创 hive建表语句
目录一、建表语句1、创建内部表2、创建外部表3、建表高阶语句 CTAS 和 WITH4、创建分区表一、建表语句1、创建内部表建表:CREATE TABLE phone_info(id int,name String,storage String,price double)ROW FORMAT DELIMITED //代表一行是一条记录FIELDS TERMINATED BY '\t'//列是按照table键分开lines terminated by '\n'将数据加进表中:hive>
2021-03-29 19:24:46
2369
原创 DBearver连接Hive
目录一、解压二、选择Apache Hive三、修改主机名、填写用户名和密码四、编辑驱动设置五、最后点击确定即可一、解压二、选择Apache Hive三、修改主机名、填写用户名和密码四、编辑驱动设置五、最后点击确定即可...
2021-03-27 23:33:34
431
原创 使用智慧星服务器运行代码步骤
1、在微信小程序租用2、使用mobaxterm连接到组用的服务器3、上传代码(图片可以压缩上传,会比较快)4、打开vcn图形化界面5、进入图像化界面之后,打开pycharm6、选编译器File>setting>plugin>interpreter>exist interpreter/root/miniconda3/bin/python37、等待文件上传好之后,可能还要重新选择一下刚刚导入的编译器,导入成功后即可使用8、注意事项:1)在main函数中加入os.env
2021-03-26 22:46:21
431
1
原创 Hive的安装和配置
目录第一步:解压第二步:创建本地文件夹第三步:配置环境变量第四步:配置文件第五步:添加`mysql`连接java(jdbc)的jar包第六步:初始化第七步:重启mysql第八步:启动hadoop第九步:检查jps最后:启动hive检查:查看数据库第一步:解压[root@hadoop2 software]# tar -zxvf hive-1.1.0-cdh5.14.2.tar.gz改名rm hive-1.1.0-cdh5.14.2 hive第二步:创建本地文件夹[root@hadoop2 hive
2021-03-26 17:39:28
381
原创 HDFS工作原理 /// 改maven工程 /// JAVA连接HDFS<重点> /// 打jar包 /// idea中设值参数
HDFS工作原理 /// JAVA连接HDFS<重点> /// 打jar包 /// idea中设值参数
2021-03-24 17:09:37
275
原创 Hadoop高可用集群配置
目录一、Hadoop高可用集群的配置第一步:配置文件第二步:删除所有机器都tmp和logs文件夹第三步:启动journalnode(所有机器都要启动)第四步:主结点操作初始化第五步:将初始化生成的tmp文件夹同步给副结点(有两种方式)第六步:主节点初始化zookeeper服务第七步:主节点启动hdfs服务:二、什么是高可用集群三、JournalNode的作用四、主节点namenode初始化的作用一、Hadoop高可用集群的配置第一步:配置文件1、 [root@hadoop2 hadoop]# vi
2021-03-22 23:16:39
872
原创 大数据概述 /// hadoop集群搭建 /// Hadoop配置JobHistory /// Hadoop常用端口号
大数据概述 ||| hadoop生态系统 ||| hadoop集群搭建 ||| Hadoop配置JobHistory ||| 端口号一、大数据是什么?二、hadoop生态系统2.1 hadoop 2.0 框架2.2 hadoop的概念官网定义:hadoop可以分为狭义和广义两种:2.3 hadoop生态系统中主要部件的介绍:Flume(日志收集工具)2.4 hadoop的三大核心组件HDFS架构HDFS写数据流程HDFS读数据流程三、hadoop集群搭建1、将已配置好的虚拟机视为主节点,克隆两台新的虚拟机
2021-03-20 11:04:43
1263
原创 Hadoop配置安装
HADOOP分布式的配置:1、解压安装包2、 改名字:3、 进入 Hadoop 文件夹下的etc 中的hadoop4、修改vi hadoop-env.sh文件5、修改vi core-site.xml文件6、修改hdfs-site.xml文件:7、修改vi mapred-site.xml.template文件:8、修改Vi /etc/profile文件:9、使配置文件生效:10、格式化HDFS11、退出到software中的hadoop文件中12、输入:ll13、启动14、到此配置完成15、若配置出错,输入J
2021-03-14 18:30:42
237
原创 Linux设置主机互信 /// 安装配置subversion(SVN) /// shell脚本
Linux设置主机互信一、设置主机互信修改主机名第一步:修改主机名的两种方式:第二步:主机列表 vi /etc/hosts 在其中加上:主机ip地址 主机名添加互信:第三步: 生成密钥:第四步:复制到密钥校验文件:第五步: 传输到需要复制的机器:第六步:测试连接主机:二、安装配置subversion(SVN)2.1 SVN是什么?2.2 SVN配置步骤一、设置主机互信修改主机名<默认的主机名是localhost.localhostDomain>第一步:修改主机名的两种方式:(1) ho
2021-03-14 18:10:42
635
原创 setAttribute、getAttribute、getParameter方法的用法 /// Session的getSession()方法的使用小结
setAttribute、getAttribute、getParameter一、setAttribute、getAttribute、getParameter**例如: servlet从请求页面中通过getParameter来获得参数****例如:跳转页面通过getAttribute来获得请求的属性二、Session的getSession()方法的使用小结一、setAttribute、getAttribute、getParametergetAttribute表示从request范围取得设置的属性,必须要先
2021-03-10 17:54:44
4407
原创 Linux入门 常用命令大全
Linux常用命令一、linux文件和目录命令二、更改、创建或删除文件夹等三、查看文件内容:四、vi/vim五、用户和用户组5.1 用户和用户组是什么?5.2 Linux操作系统用户的特点如下:5.3 权限管理5.4 Chmod用户及用户组的权限一、linux文件和目录命令cd /home 进入 ‘/ home’ 目录’cd … 返回上一级目录cd …/… 返回上两级目录cd 进入个人的主目录cd ~user1 进入个人的主目录cd - 返回上次所在的目录二、更改、创建或删除文件夹等pwd
2021-03-10 17:13:29
1038
原创 JavaWeb /// JDBC连接数据库 /// DAO设计模式访问Mysql数据库 /// DAO设计模式demo /// Servlet
Java Web、DAO设计模式(访问Mysql数据库)一、DAO设计模式1.什么是DAO?2.使用Dao模式的好处3.DAO模式主要组成部分二、实例:DAO设计模式demo -- 使用‘数据库连接类’连接MySql数据库并实现在网页上注册用户(即添加用户到数据库)一、DAO设计模式1.什么是DAO?DAO模式提供了访问关系型数据系统所需操作的接口,将数据访问和业务逻辑分开,对上层提供面向对象的数据访问接口.2.使用Dao模式的好处在编写了dao模式以后,就使得代码变得模块化,更有利于代码的维护和
2021-03-08 17:52:24
946
1
原创 牛客刷题---重点复习
牛客刷题---重点复习题1:在牛客刷题有一个通过题目个数的(passing_number)表,id是主键,简化如下:题1:在牛客刷题有一个通过题目个数的(passing_number)表,id是主键,简化如下:select b.id,b.number, count(distinct a.number) t_rankfrom passing_number ajoin passing_number b where a.number>=b.numbergroup by b.number,b.i
2021-03-07 17:08:44
316
2019年第十六届中国研究生数学建模竞赛F题 多约束条件下智能飞行器航迹快速规划.rar
2020-09-24
Matlab2018a 64bit 安装步骤.docx
2020-09-22
五种信件(邀请信、接受函、拒绝信、申请信、备忘录)
2020-08-31
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人