- 博客(37)
- 收藏
- 关注
 RSS订阅
RSS订阅原创 java object对象大小
对象头又包括三部分:MarkWord、元数据指针、数组长度。MarkWord: 用于存储对象运行时的数据,好比 HashCode、锁状态标志、GC分代年龄等。这部分在 64 位操作系统下占 8 字节,32 位操作系统下占 4 字节。指针: 对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪一个类的实例。这部分就涉及到指针压缩的概念,在开启指针压缩的状况下占 4 字节,未开启状况下占 8 字节。数组长度: 这部分只有是数组对象才有,若是是非数组对象就没这部分。这部分占 4 字节。.
2021-11-02 11:23:02
 848
848
原创 jvm指令与工具jstat/jstack/jmap/jconsole/jps/visualVM
一、jps 打印java进程基本信息二、*jconsole java性能分析器可以执行gc查看线程类jvm概要三、jstat 轻量级小工具jstat -gcutil 8208 1000 该命令为打印gc情况,显示百分比8208为进程号,1000为每隔1000毫秒打印一次jstat -gc 8208jstat -gcnew 8208 1000jstat -gcold 8208 1000查看young和old区四、jstack 查看线程情况jstack 8
2021-10-25 15:18:34
206
原创 mongodb学习笔记
一、mongo集群方式1. 主从方式 (非对称方式)在主从结构中,主节点的操作记录成为oplog(operation log)。oplog存储在一个系统数据库local的集合oplog.$main中,这个集合的每个文档都代表主节点上执行的一个操作。从服务器会定期从主服务器中获取oplog记录,然后在本机上执行!对于存储oplog的集合,MongoDB采用的是固定集合,也就是说随着操作过多,新的操作会覆盖旧的操作!2. 副本集(Replica Sets)mongodb 不推荐主从复制,推荐建立副
2021-10-20 16:04:58
216
原创 redis学习笔记
一、缓存过期后没释放内存定期删除+惰性删除定期删除指的是Redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。为什么是随机抽取?假设Redis里放了10万个key,都设置了过期时间,你每隔几百毫秒,就检查10万个key,那redis基本上就死了,因为这样cpu负载会很高的,全都消耗在你的检查过期key上了。所以这里可不是每隔100ms就遍历所有的设置过期时间的key,Redis如果设置成检查所有Key那将是一场性能上的灾难。所以实际上redis是每隔
2021-10-20 15:25:11
136
原创 JVM线上排查问题常用办法
一、CPU100%问题查找进程当发现CPU过高之后,首先我们要找出哪个进程占用了CPU。我们可以使用top命令top -c在显示模式下,然后我们可以通过切换到大写,不断的按大写P就能进行排序,找到最大的CPU看看上哪个进程。查找线程我们已经找到了哪个进程最消耗CPU了,接下来,我们当然要找到该进程下,哪个线程CPU消耗最高咯。这里的进程PID是7,使用命令top -Hp 7到此我们已经定位到线程了,接下来我们就该用上jvm的命令工具了。然后我们使用jstack命令,拉到7进程快照
2021-10-20 11:21:16
448
原创 jvm参数设置
一、堆参数设置-XX:+PrintGC 使用这个参数,虚拟机启动后,只要遇到GC就会打印日志-XX:+UseSerialGC 配置串行回收器-XX:+PrintGCDetails 可以查看详细信息,包括各个区的情况-Xms:设置Java程序启动时初始化堆大小-Xmx:设置Java程序能获得最大的堆大小-Xmx20m -Xms5m -XX:+PrintCommandLineFlags:可以将隐式或者显示传给虚拟机的参数输出二、新生代参数配置-Xmn:可以设置新生代的大小,设置一个比较大的新生代
2021-10-20 10:35:02
3006
原创 聚簇索引与非聚簇索引
1.对于非聚簇索引表来说(右图),表数据和索引是分成两部分存储的,主键索引和二级索引存储上没有任何区别。使用的是B+树作为索引的存储结构,所有的节点都是索引,叶子节点存储的是索引+索引对应的记录的数据。2.对于聚簇索引表来说(左图),表数据是和主键一起存储的,主键索引的叶结点存储行数据(包含了主键值),二级索引的叶结点存储行的主键值。使用的是B+树作为索引的存储结构,非叶子节点都是索引关键字,但非叶子节点中的关键字中不存储对应记录的具体内容或内容地址。叶子节点上的数据是主键与具体记录(数据内容)。...
2021-10-11 15:08:57
123
原创 各种排序算法
1、插入排序遍历所有的值,每一个都插入到之前已经排好的队列中的合适位置对于基本有序的数列排序,性能比较好2、希尔排序(插入排序的改良版)在插入排序之前,先按照一定的步长,把数列用插入排序排好,再逐渐减少步长,直到步长为1。比插入排序多的步骤主要是为了,先初步排一下序,方便最后的插入排序。对于基本有序的数列排序,性能比较好3、冒泡排序重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算.
2021-10-07 19:32:47
1059
原创 数据库索引为什么不用二叉平衡树
逻辑上,二叉平衡树的查找次数和效率是最高的,但现实中,数据库索引是保存在磁盘中的,所以为了减少io的次数,从而放弃二叉平衡树,改用B+树,减少io次数。
2021-10-07 16:17:11
248
原创 B-树,B+树学习笔记
B-树(Balance Tree),一个m阶的B树具有如下几个特征:1.根结点至少有两个子女。2.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m3.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m4.所有的叶子结点都位于同一层。5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。一个三叉B-树...
2021-10-07 16:16:01
128
原创 synchronized的实现过程
java代码:加上synchronized字段class字节码:monitorenter与monitorexit指定加锁的代码的范围执行过程中,锁会升级(无锁-偏向锁-自旋锁-重量级锁)汇编语言:使用lock-cmpxchg实现
2021-10-05 17:00:22
130
原创 java锁升级的过程
锁的4中状态:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态(级别从低到高)一、锁升级为什么要引入偏向锁?因为经过HotSpot的作者大量的研究发现,大多数时候是不存在锁竞争的,常常是一个线程多次获得同一个锁,因此如果每次都要竞争锁会增大很多没有必要付出的代价,为了降低获取锁的代价,才引入的偏向锁。偏向锁的升级当线程1访问代码块并获取锁对象时,会在java对象头和栈帧中记录偏向的锁的threadID,因为偏向锁不会主动释放锁,因此以后线程1再次获取锁的时候,需要比较当前线程的thr
2021-10-05 16:45:12
2645
原创 cas笔记
JUC下的atomic类都是通过CAS来实现的,比如AtomicIntegerAtomicInteger 类调用incrementAndGet()方法实现原子性的自增,内部调用Unsafe的getAndAddInt方法:public final int incrementAndGet() { return unsafe.getAndAddInt(this, valueOffset, 1) + 1;}在Unsafe类的getAndAddInt方法中主要是看compareAndSwapInt方
2021-10-05 02:10:59
160
原创 分布式id生成的若干方案
1. UUID在Java的世界里,想要得到一个具有唯一性的ID,首先被想到可能就是UUID,毕竟它有着全球唯一的特性。那么UUID可以做分布式ID吗?答案是可以的,但是并不推荐!public static void main(String[] args) { String uuid = UUID.randomUUID().toString().replaceAll("-",""); System.out.println(uuid); }UUID的生成简单到只有一行代
2021-10-05 00:16:25
135
原创 HashMap与HashTable的区别
HashMap线程不安全允许有null的键和值效率高一点、方法不是Synchronize的要提供外同步有containsvalue和containsKey方法HashMap 是Java1.2 引进的Map interface 的一个实现HashMap是Hashtable的轻量级实现Hashtable线程安全不允许有null的键和值效率稍低、方法是是Synchronize的有contains方法方法Hashtable 继承于Dictionary 类Hashtabl...
2021-10-03 21:38:26
93
原创 分布式事务seata学习笔记
0.学习目标了解分布式事务产生的原因知道几种分布式事务解决方案:XA、TCC、消息事务、TA、SAGA知道分布式事务各种解决方案的优缺点和使用场景学会使用Seata来解决分布式事务1.什么是分布式事务要了解分布式事务,必须先了解本地事务。1.1.本地事务本地事务,是指传统的单机数据库事务,必须具备ACID原则:原子性(A)所谓的原子性就是说,在整个事务中的所有操作,要么全部完成,要么全部不做,没有中间状态。对于事务在执行中发生错误,所有的操作都会被回滚,整个事务就像从没被执行过一
2021-09-28 10:58:58
693
转载 Tcp三次握手,四次挥手的形象比喻
在一篇博客的评论上看到的,觉得不错,再次记录下来3次握手就跟早期打电话时的情况一样:1、听得到吗?2、听得到,你呢?3、我也听到了。然后才开始真正对话 。。。。4次挥手是:1、老师,下课了。2、好,我知道了,我说完这点。3、好了,说完了,下课吧。4、谢谢老师,老师再见4次挥手是:1、客户端:你还有什么要说的吗?没什么就挂了2、服务器:好的,我知道了,我想一想还有什么要说的 …中间可能还会有其他数据通信,但只能是服务器发送,客户端接收了,客户端不能再“说”了3、服务器:哦
2021-09-26 14:21:37
441
原创 java类加载子系统学习笔记
类加载子系统类加载的过程 (加载,链接,初始化)加载阶段通过一个类的全限定名获取定义此类的二进制字节流 (例如: 类.class 获取二进制字节流)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构 (看具体jvm的版本,所具体的方法区运行的数据结构不同)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口(在内存中生成类的模板,可以被随时调用,也是反射的原理)加载class文件的方式从本地系统中直接加载通过网络获取,典型场
2021-08-16 17:22:51
103
原创 spring源码学习笔记(流程图)
spring源码学习笔记(流程图)https://www.processon.com/view/link/611a234fe401fd4e2704610b若有错误之处,望大神不吝赐教
2021-08-16 16:42:57
178
原创 java反射笔记
文章目录反射泛型构造方法反射泛型构造方法一个泛型类只有唯一的构造器,并且构造器带有泛型形参。反射该类的构造器时getConstructor(String.class,Object.class)方法中,泛型对应的应天Object.classpackage com.zys.aoptest.pojo;import java.lang.reflect.Constructor;import ...
2020-04-16 17:46:59
141
原创 java自定义注解及使用场景(并学习:拦截器+AOP)
文章目录一、什么是注解(Annotation)二、注解体系图三、常用元注解Java自定义注解一般使用场景为:自定义注解+拦截器或者AOP,使用自定义注解来自己设计框架,使得代码看起来非常优雅。本文将先从自定义注解的基础概念说起,然后开始实战,写小段代码实现自定义注解+拦截器,自定义注解+AOP。一、什么是注解(Annotation)Java注解是什么,以下是引用自维基百科的内容Ja...
2020-04-15 16:48:08
1379
原创 java枚举类型及枚举集合
文章目录一、枚举类型二、switch 操作三、自定义枚举类四、相关枚举类4.1 EnumMap 枚举型映射/字典一、枚举类型/** * @author zhangys * @description * @date 2020/4/15 */public class EnumTest { enum Day { SUNDAY, TUESDAY, WEDNESDAY...
2020-04-15 15:29:28
3453
原创 国土项目添加SpringBoot-Admin
一、设置服务端应用程序(Spring Boot Admin Server)首先,您需要设置您的服务器。 要做到这一点,只需设置一个简单的启动项目。1、将Spring Boot Admin Server启动器添加到您的依赖项:pom.xml<dependencies> <dependency> <groupId>de.codecen...
2020-04-02 16:45:16
171
原创 Dubbo学习笔记
目录一、基础知识1、分布式基础理论1.1 什么是分布式1.2 发展演变1.3 RPC2、Dubbo核心概念3、注册中心:zookeeper下载及安装4、监控中心一、基础知识1、分布式基础理论1.1 什么是分布式分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统。分布式系统(distributed system)是建立在网络之上的软件系统。1.2 发展演变1.3...
2020-03-30 12:05:55
199
原创 java开发手册
目录一、编程规约1、命名风格1.1 领域模型命名规约1.2 中括号是数组类型的一部分,数组定义如下:String[] args; 反例:请勿使用 String args[]的方式来定义。1.3 枚举类名建议带上 Enum 后缀,枚举成员名称需要全大写,单词间用下划线隔开。2、常量定义2.1 常量的复用层次有五层:跨应用共享常量、应用内共享常量、子工程内共享常量、包 内共享常量、类内共享常量。2.2...
2020-03-26 17:39:14
1864
原创 决策树
目录1.计算给定数据集的经验熵(香农熵)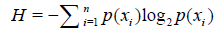2.计算信息增益,并选择最优特征3.决策树的生成和修剪4.使用决策树执行分类5.完整代码6.Sklearn构建决策树分类器预测隐形眼镜类型1.计算给定数据集的经验熵(香农熵)"""Parameters: dataSet ...
2020-03-19 18:16:33
178
原创 Sklearn构建k-近邻分类器用于手写数字识别
目录1.准备数据:将图像转换为测试向量2.测试算法:使用k-近邻算法识别手写数字k-近邻算法总结示例:使用k-近邻算法的手写识别系统(1) 收集数据:提供文本文件。(2) 准备数据:编写函数classify0(),将图像格式转换为分类器使用的list格式。(3) 分析数据:在Python命令提示符中检查数据,确保它符合要求。(4) 训练算法:此步骤不适用于k-近邻算法。(5) 测试算...
2020-03-13 14:18:45
712
原创 sklearn笔记
目录neighborsKNeighborsClassifierneighborsKNeighborsClassifierclass sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30,p=2, metric=’minkowski’, me...
2020-03-13 14:10:08
215
原创 k-近邻算法改进约会网站的配对效果笔记
目录前言1.准备数据:从文本文件中解析数据2.分析数据:使用Matplotlib 创建散点图3.准备数据:数据归一化4.测试算法:作为完整程序验证分类器前言这里是一个比较有意思的话题产生的例子,也就是婚介网站等等的约会网站帮助你相亲,我的朋友海伦就是这样一个人,她一直使用在线约会网站寻找适合自己的约会对象,但是她发现尽管约会网站会推荐不同的人选,但并不是每一个人她都喜欢。经过一番总结,她发现曾...
2020-03-11 17:29:18
342
原创 python基础
目录数组[:,0]数组[:,0]X[:,0]就是取所有行的第0个数据, X[:,1] 就是取所有行的第1个数据。X[0,:]就是取所有列的第0个数据, X[1,:] 就是取所有列的第1个数据。...
2020-03-10 13:58:55
369
原创 k-近邻算法预测电影类型
目录每部电影的打斗镜头数、接吻镜头书以及电影评估类型根据两点距离公式(欧氏距离公式),预测值与每个点的距离完整代码每部电影的打斗镜头数、接吻镜头书以及电影评估类型根据两点距离公式(欧氏距离公式),预测值与每个点的距离完整代码import numpy as npimport operator"""Parameters: 无Returns: group - 数据集...
2020-03-10 13:02:40
718
![]()
空空如也
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人