Creating a Web Project: Caching for Performance Optimization
Caching boosts performance by cutting server load and speeding responses. This article covers key caching strategies to help optimize your project efficiently.
Join the DZone community and get the full member experience.
Join For FreeIn one of the previous articles on identifying issues in your project, “Creating a Web Project: Key Steps to Identify Issues,” we discussed how to analyze application performance and how collecting metrics can assist in this task. However, identifying a problem is only the first step; action must be taken to resolve it. Caching is arguably one of the most effective and widely used methods for accelerating your application.
The principle behind it is that instead of performing complex operations each time, we temporarily save the result of those operations and return it for subsequent similar requests if the inputs have not changed. This way, the application can be sped up, load reduced, and overall stability improved.
However, like any tool, caching should be used wisely. Let us see if it can help your particular project and find out what you should do next if the answer is positive.
Cache Is King... Or Is It?
The general reasons for optimising your application are straightforward. First, the responsiveness of your service will increase, and the user experience will improve. In turn, this can positively influence the product metrics of the system and key indicators such as revenue. Second, the system will become more fault-tolerant and capable of withstanding higher loads. Third, by optimizing your project, you can reduce infrastructure costs.
However, it is always important to remember that premature optimization is a bad practice, and such matters must be approached thoughtfully. Every method that improves system performance also increases the complexity of understanding and maintaining it. Therefore, let me emphasize once again: first, learn how to analyze how your system currently works and identify its bottlenecks. Only then should you begin optimization.
Caching should be applied only when:
- Requests to slow data stores or complex operations are frequently repeated with the same parameters.
- The data is not updated too often.
- The system's slow performance is causing issues.
If you checked all three boxes on the list, let us proceed. The next thing to keep in mind is that you should not overuse caching. By adding it, you also take on tasks related to cache invalidation, application debugging, and increased complexity of understanding the application.
Caching can be used in various parts of a system, and it can occur at many levels: client-side, network, server-side, application-level, and more. Each of these levels can have multiple sub-levels of caching. This can somewhat resemble a large onion, with each layer capable of caching data to accelerate the entire system. To fully cover the topic of caching, an entire book might not be enough, but in this article, let’s highlight the key points that a web developer needs to understand when building an application.
Client-Side Caching
One of the most obvious mechanisms encountered by every internet user daily is client-side caching, for example, in the browser. In such cases, requests do not even reach the server: data is instantly returned from the local cache, providing maximum response speed and reducing server load.
Even backend developers must understand how client-side caching works, since the backend can influence its behavior using special HTTP headers. Client-side caching can exist at different levels: in the frontend application's code, the library sending the requests, or the browser itself. So while direct control from the backend is not possible, indirect management is quite feasible.
Among the headers that affect caching, the main ones are: Cache-Control, Last-Modified, ETag, and Expires. With these, the server can tell the client which content can be cached and for how long it can be used without a new request. This effectively reduces traffic and improves performance for both the client and the server.
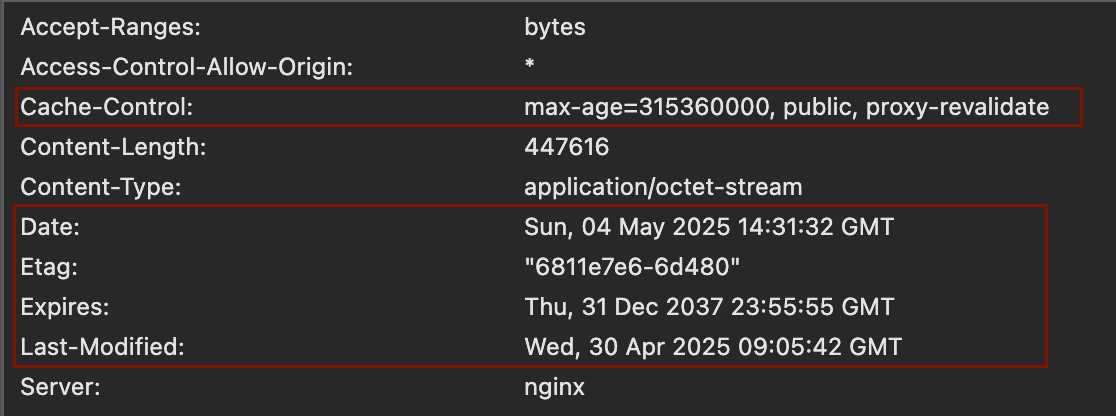
For instance, static files such as styles or JavaScript scripts are often cached. However, there are cases where the cache needs to be forcibly cleared before its expiration. To do this, the technique known as cache busting is used — a special GET parameter is added to the URL (for example, ?v=1234). Changing this parameter forces the client to re-download the file, even if the previous version is still stored in the cache, because even a minor change in the URL is considered a new URL from the web’s perspective.
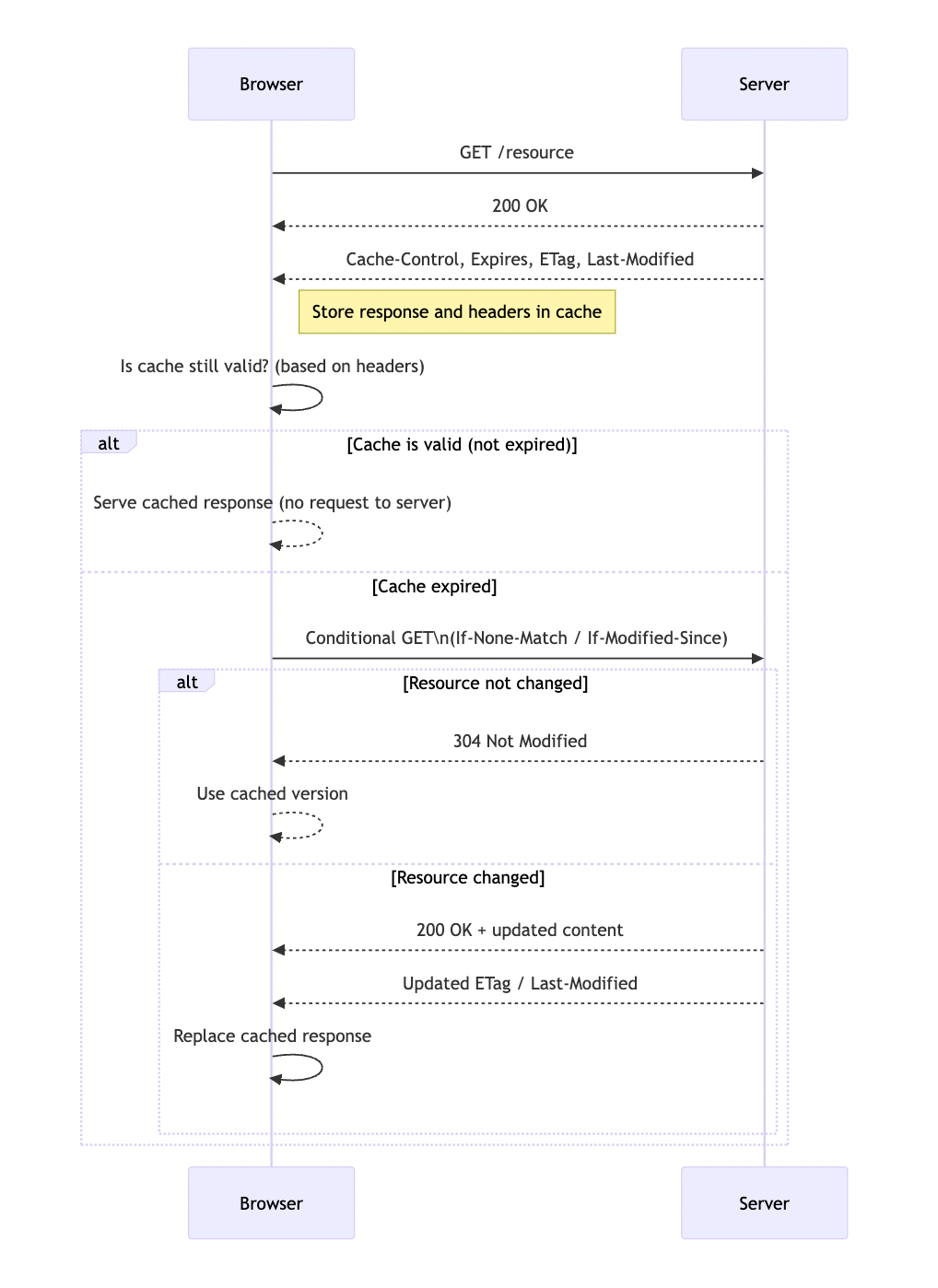
Incidentally, caching is applicable not only to static files; it can also be effectively used for API endpoints to reduce the number of calls to your (or a third-party) server, thereby lowering load and increasing application responsiveness. This is also relevant when interacting between two backends, where one plays the role of the client: in such cases, the number of network requests can be significantly reduced, lightening the infrastructure load. Proper use of HTTP headers allows for cache behavior control even in such scenarios and enhances the overall robustness of the system.
Here are the main prerequisites for client-side caching to be effective:
- Use caching headers (Cache-Control, Last-Modified, ETag, Expires) for both static resources and applicable API methods.
- When calling APIs from your backend, consider cache headers and cache results where appropriate.
- Plan a cache invalidation strategy on the client in advance, and if necessary, apply cache busting techniques (e.g., via URL parameters).
Network-Level Caching
Network-level caching means data is cached between the client and server to reduce the number of server requests and accelerate content delivery. This could involve using a CDN (Content Delivery Network), such as Cloudflare or Fastly.
With such tools, caching rules can be configured quite flexibly: any endpoints can be cached for any desired duration, and the cache can be cleared or rules adjusted via API. Additionally, these services offer flexible configuration of DNS record TTLs.
To maximize the benefits of network-level caching with minimal costs, please keep these points in mind:
- Use only popular CDN services – this ensures fast and reliable delivery of static resources to users around the world, reducing latency and server load.
- Configure caching rules flexibly for individual endpoints when necessary – this is especially important for dynamic data with varying update frequencies.
- Document cache logic and refresh rules – this simplifies maintenance, reduces errors, and ensures transparency across all internal teams.
- Consider evaluating alternative CDN services aside from the one you’ve selected, but avoid becoming overly dependent on custom features to prevent vendor lock-in.
- Don’t forget to set a reasonable TTL for DNS records. A long TTL will reduce periodic delays when loading your web project, but changing the IP address may become more difficult, so reduce the TTL in advance when preparing for migrations.
Server-Side Caching
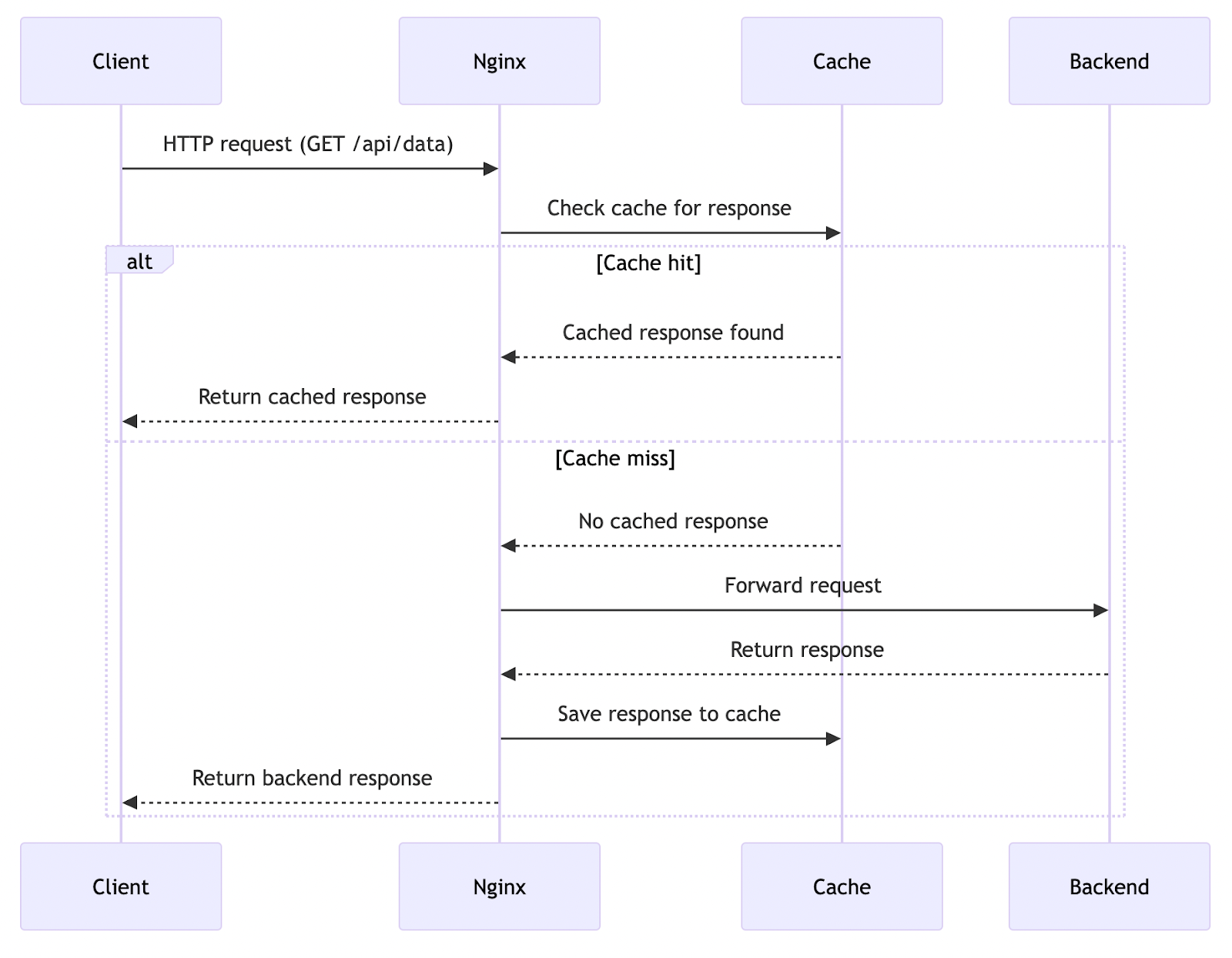
Server-side caching (infrastructure-level, outside the application code) can also significantly improve performance. In this case, data is cached at the web server level, and the request might not even reach the application’s business logic — the response is returned from the cache. This reduces application load and accelerates processing of repeated requests.
There are ready-made tools for this approach, such as Nginx cache, if you use Nginx as your web server. Here’s an example:
http {
proxy_cache_path /data/nginx/cache keys_zone=mycache:10m inactive=10m max_size=100m;
server {
listen 80;
server_name shcherbanich.com;
location ~ ^/api/ {
proxy_pass http://localhost:8000;
proxy_cache mycache;
proxy_cache_valid 200 5m;
proxy_cache_methods GET HEAD;
proxy_cache_use_stale error timeout updating;
add_header Cache-Control "public, max-age=300";
add_header X-Cache-Status $upstream_cache_status;
}
}
}In this example, caching is configured for API endpoints in Nginx for the GET and HEAD methods, where all requests to paths starting with /api/ are proxied to a local backend (localhost:8000), and successful responses (status code 200) are cached on disk for 5 minutes. The cache is handled by the mycache zone, configured with a 100 MB limit and 10 MB of RAM for metadata.
The browser is explicitly informed of the caching capability through the Cache-Control: public, max-age=300 header, while the X-Cache-Status header allows tracking whether the response was retrieved from the cache. In case of errors or timeouts, Nginx will serve whatever is in the cache, even outdated information, if available.
Today, all popular web servers offer very flexible caching options for applications, and given their incredible performance, this method can often be used to optimize your service with minimal effort. That’s why I recommend not ignoring this opportunity, but don’t forget to document this behavior, especially if the configuration is stored separately from your project code. Adding caching logic outside the application level may complicate the team’s understanding of how the system works.
Also, don’t forget this:
- Caching can be implemented at the web server level – this is an effective way to reduce system load.
- API endpoints can also be cached, but this should be done carefully, taking into account the risks of stale data and debugging complexities.
- Server-side caching allows for serving cached responses even when the backend fails, increasing fault tolerance.
Application-Level Caching
At the application level, you can cache both individual business logic operations and virtually any data – you have full control. Most often, database query results or responses from external APIs are cached to reduce response times and system load. However, there are also cases where even internal application logic is so resource-intensive that it makes sense to cache it.
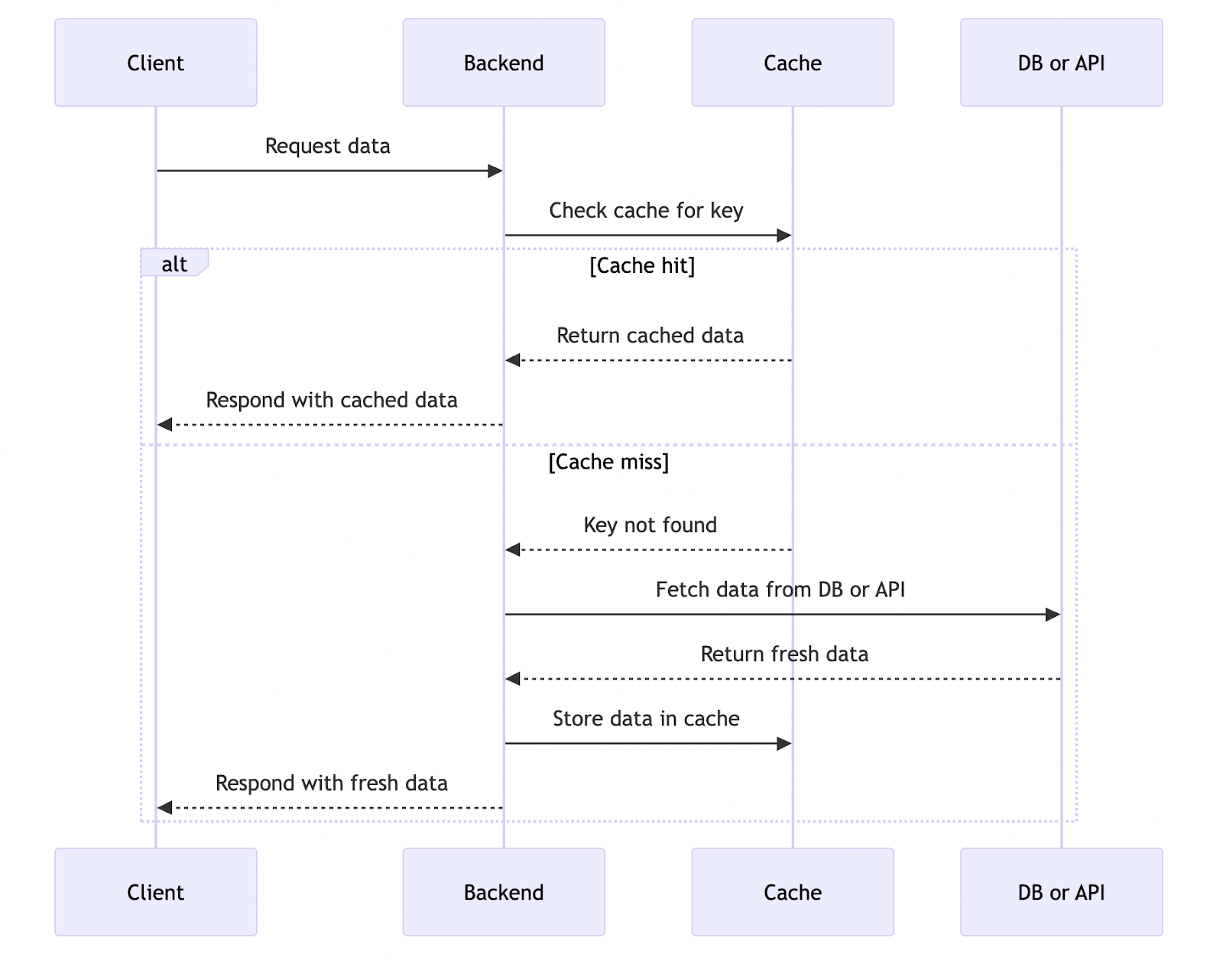
In such cases, storage solutions like Redis, Memcached, or Valkey (a Redis 7.2 fork supported by the Linux Foundation) are commonly used — these are high-performance key/value stores. Redis and Valkey, in particular, offer a rich set of features, such as support for structured data types (strings, lists, sets, hashes, sorted sets), pub/sub mechanisms, streams, Lua scripting, and TTL settings for automatic key expiration. This makes them suitable not only for basic caching but also for implementing queues, rate-limiting, and other tasks requiring fast processing and temporary data storage.
However, using external stores like Redis is not always necessary. You can implement caching in the application’s memory if it runs continuously in a single process. File-based caching is also possible: if implemented correctly, it can be just as fast, and in some cases even outperform external solutions (especially if the external store is hosted remotely). Nonetheless, such approaches are not scalable and require manual management and maintenance, especially in distributed environments.
Please remember:
- Application-level caching allows you to store the results of resource-hungry operations (database queries, external APIs, calculations), thereby significantly speeding up the application.
- You have full control over caching logic: conditions, storage format, lifetime, and invalidation methods — app-side caching is your best friend.
- Plan methods for analyzing cache state, collect metrics, and monitor server resources.
Final Thoughts
It is important to always take a well-considered approach to caching: careless use can complicate debugging, lead to elusive bugs, and cause memory overflows. When caching, always remember to care about cache invalidation strategies, memory limits for cache storage, and ways to maintain cache consistency.
Don’t blindly add caching everywhere — it’s better to do so gradually and only when performance problems arise. Be capable of measuring your system’s performance: even before implementing caching, analyze request volume, memory/CPU usage, and request processing speed. After implementation, add metrics such as the number of items in cache, cache hit rate, eviction rate, number of cache-related errors, and expired rate (items removed due to TTL expiration).
We have reviewed the most fundamental method of optimizing your application. In the next part, we will discuss other popular and important optimization techniques.
Resources
Opinions expressed by DZone contributors are their own.
Comments