Introducing Graph Concepts in Java With Eclipse JNoSQL
Harness the power of graph databases in Java using Eclipse JNoSQL and Jakarta Data — model rich relationships with Neo4j or TinkerPop and write smarter, connected apps.
Join the DZone community and get the full member experience.
Join For FreeWhen we talk about databases today, we face a landscape of diversity. Gone are the days of a one-size-fits-all solution. We live in an era of polyglot persistence, where the guiding principle is to use the most appropriate data model for each use case. This article focuses on graph databases, their structure, practical applications, and how Java developers can leverage Eclipse JNoSQL and Jakarta Data to work seamlessly with them.
Graph databases enable richer and more natural modeling of connected data. Unlike traditional relational databases that require complex joins to represent relationships, graph databases make relationships first-class citizens. A graph model organizes data into vertices (nodes) and edges (relationships). Both vertices and edges can hold properties, and edges are directional, adding semantic meaning to how data points connect.
Consider a relational table that references itself to build a hierarchy, or a schema involving several many-to-many tables. These patterns can become cumbersome and inefficient. Graph databases solve this by modeling relationships explicitly, making traversals faster and queries more intuitive.
To better illustrate the differences between relational and graph databases in such scenarios, the following table summarizes how each approach models and queries data:
| Concept | Relational Database | Graph Database |
|---|---|---|
| Entity | Table row | Vertex |
| Relationship | Foreign key / Join table | Edge (first-class, with direction and properties) |
| Self-reference (hierarchies) | Recursive joins | Direct edges between nodes |
| Many-to-many relationships | Join tables | Edges with labels and attributes |
| Query language | SQL | Gremlin (TinkerPop) / Cypher (Neo4j) |
| Query performance (deep links) | Degrades with depth | Optimized via index-free adjacency |
| Schema flexibility | Rigid schema | Flexible with property schema |
This strength becomes apparent in use cases like social networks (friend-of-a-friend), recommendation systems, fraud detection, and hierarchical data representations like organizational structures.
While SQL is the universal query language for relational databases, NoSQL systems — especially graph databases — do not follow a single standard. However, two dominant approaches exist:
- Apache TinkerPop offers the Gremlin query language and is supported by over 30 graph databases, including JanusGraph and Amazon Neptune. It defines graph traversals using a functional style, offering flexibility and power to query large, complex graphs.
- OpenCypher, originating from Neo4j, provides a declarative, SQL-like syntax that’s often easier to read and write. Neo4j is the most popular graph database, with strong tooling and ecosystem support.
| Feature | TinkerPop (Gremlin) | OpenCypher |
|---|---|---|
| Language Style | Functional API | Declarative, SQL-like |
| Ecosystem | JanusGraph, Neptune, etc. | Neo4j |
| Syntax Complexity | Moderate to High | Low |
| Learning Curve | Steeper | Gentler |
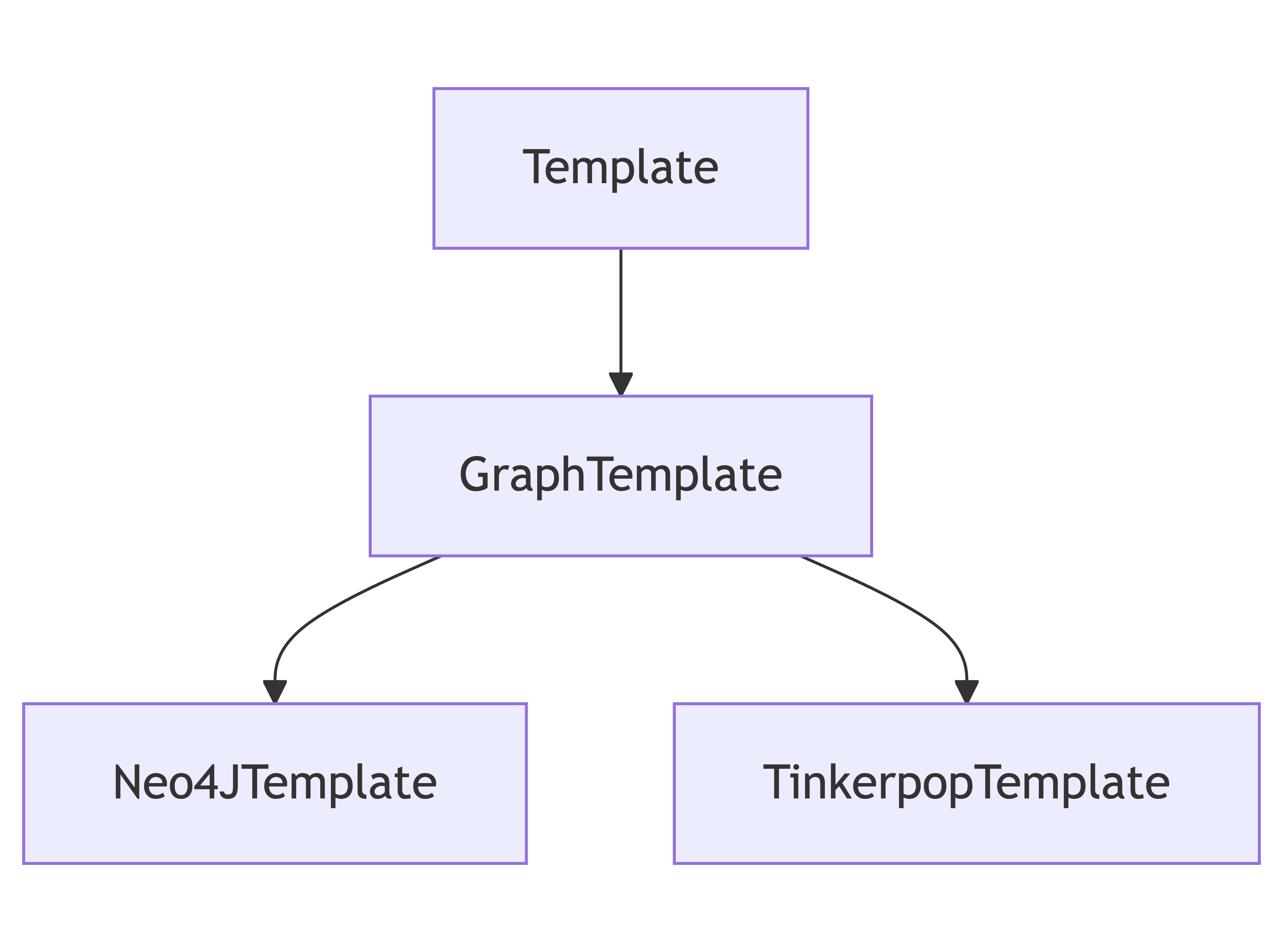
Eclipse JNoSQL 1.1.8 introduces a unified way to interact with Gremlin and Cypher-based databases to simplify development. The GraphTemplate API provides a neutral abstraction, while Neo4JTemplate and TinkerpopTemplate allow you to take advantage of each database's capabilities fully.
In the sample projects available at https://github.com/soujava/intro-graph-2025, you will find implementations using both Neo4j and JanusGraph. The entity classes are structured similarly using Jakarta annotations:
//Neo4J
@Entity
public class Book {
@Id
private String id;
@Column
private String name;
}
@Entity
public class Category {
@Id
private String id;
@Column
private String name;
}
//Apache Tinkerpop
@Entity
public class Book {
@Id
private String id;
@Column
private String name;
}
@Entity
public class Category {
@Id
private String id;
@Column
private String name;
}Despite differences such as String vs Long for ID types, the overall model remains consistent across databases. These classes represent the vertices. Inserting them is straightforward and follows a familiar pattern if you have used any NoSQL database:
Template template = ...;
var book = template.insert(Book.of("Effective Java"));
Optional<Book> bookFromDatabase = template.find(Book.class, book.getId());To represent relationships (edges), you can use the GraphTemplate, which is a specialization of Template; thus, it includes the Edge capability on the NoSQL database:
GraphTemplate template = ...;
var book = template.insert(Book.of("Effective Java"));
var category = template.insert(Category.of("Java"));
Edge<Book, Category> edge = Edge.source(book)
.label("is")
.target(category)
.property("relevance", 10)
.build();
template.edge(edge);If you need to execute native queries, you can use the specialized templates. The architecture starts with the Template Interface from the Jakarta NoSQL specification, which provides a generic abstraction for NoSQL operations. This interface defines foundational methods for persisting and retrieving entities across different NoSQL databases.
On top of this abstraction, Eclipse JNoSQL introduces the GraphTemplate, a specialization that focuses on graph-related capabilities, enabling operations on vertices and edges. It allows developers to work with graph semantics in a unified way.
Beyond that, JNoSQL offers even more specialized APIs: Neo4JTemplate and TinkerpopTemplate. These implementations expose database-specific capabilities and query languages — namely Cypher for Neo4J and Gremlin for Apache TinkerPop — allowing you to write expressive, powerful queries tailored to the graph engine in use. These templates are essential when you need to fully leverage the native graph query power of your chosen database.
TinkerpopTemplate tinker = ...;
var books = tinker.gremlin(
"g.E().hasLabel('is').has('relevance', gte(9))"
+ ".outV().hasLabel('Book').dedup()"
).toList();
Neo4JTemplate neo4j = ...;
var books = neo4j.cypher(
"MATCH (b:Book)-[r:is]->(:Category) WHERE r.relevance >= 9 RETURN DISTINCT b",
Collections.emptyMap()
).toList();Jakarta Data further streamlines this by allowing you to define repository interfaces. There are three ways to query data:
- Method name-based queries
@Findannotation for dynamic queries@Queryannotation for execute Jakarta Data Query language
Each approach has its trade-offs. Using Jakarta Data's method-name queries or the @Find annotation offers a unified experience across graph databases, but limits access to database-specific features. Conversely, the specializations enable full access to Gremlin or Cypher, unlocking advanced querying capabilities at the cost of portability.
@Repository
public interface BookRepository extends TinkerPopRepository<Book, String> {
@Gremlin("g.V().hasLabel('Book').out('is').hasLabel('Category').has('name','Architecture').in('is').dedup()")
List<Book> findArchitectureBooks();
@Gremlin("g.E().hasLabel('is').has('relevance', gte(9)).outV().hasLabel('Book').dedup()")
List<Book> highRelevanceBooks();
}
@Repository
public interface BookRepository extends Neo4JRepository<Book, String> {
@Cypher("MATCH (b:Book)-[r:is]->(:Category) WHERE r.relevance >= 9 RETURN DISTINCT b")
List<Book> highRelevanceBooks();
}Alternatively, a Jakarta Data query method might look like the example below. However, it is essential to understand that Jakarta Data is limited to querying vertices (entities) and cannot directly express or manipulate edges, fundamental relationships in graph databases.
This means that while Jakarta Data supports standard query methods like method-name queries, @Find, and @Query using its portable query language, it does not cover the graph-specific semantics, such as inserting or querying relationships. For those cases, you must rely on database-specific APIs like Gremlin and Cypher:
@Repository
public interface BookRepository extends Repository<Book, String> {
List<Book> findByName(String name);
@Query("from Book where name = :name")
List<Book> query(@Param("name") String name);
}Graph databases bring powerful relationship modeling to software design, especially with deep and complex data interconnections. With Eclipse JNoSQL and Jakarta Data, Java developers gain a unified, flexible API that balances ease of use with deep integration. Whether you choose TinkerPop’s Gremlin or Neo4j’s Cypher, you’ll find a robust foundation for building modern, graph-powered applications.
References
- Robinson, I., Webber, J., Eifrem, E. (2015). Graph Databases. O'Reilly Media.
- Fowler, M. (2002). Patterns of Enterprise Application Architecture. Addison-Wesley.
- Kleppmann, M. (2017). Designing Data-Intensive Applications. O'Reilly Media.
- Apache TinkerPop
- Neo4j Docs
- Jakarta EE
- Eclipse JNoSQL
- JNoSQL Examples Code
Opinions expressed by DZone contributors are their own.
Comments