Driving DevOps With Smart, Scalable Testing
DevOps thrives on fast, reliable releases — and that means better testing. Automation across APIs, code, and E2E flows helps catch bugs early and ship confidently.
Join the DZone community and get the full member experience.
Join For FreeDevOps practices can require software to be released fast, sometimes with multiple deployments throughout the day. This is critical to DevOps, and to accomplish it, developers must test in minutes to determine if software will move forward, be sent back to the drawing board or canned altogether. Identifying and correcting bugs prior to production is essential to the Software Development Life Cycle (SDLC) and testing should play a part in all processes.
During the test phase, integrating automated testing when possible is critical, with the choice of approach tailored to the specific application’s structure. This could involve focusing on public methods for APIs, verifying code and components or implementing comprehensive end-to-end (E2E) assessments. Emphasizing a thorough testing process ensures all aspects, such as units or methods, and integration between internal system components and frontend and backend parts.
Further, structured test management systems help provide comprehensive reporting and clear communication about outcomes and development progress. This keeps the entire team informed and aligned with the application’s ongoing status.
Yet, no matter the deadline or tool used, an organization must be hyperfocused on quality. With this in mind, testing should no longer be exclusive to Quality Assurance (QA) Teams: Engineers should participate and be held accountable as well. Shared responsibility delivers consistently reliable results, weeding out issues before they take root and waste resources. Quality is a responsibility of the whole R&D organization, working closely with business and product teams. Automation speeds up cycles and mitigates human error, and automated testing identifies defects in code or integration between different system components.
A good example of this is a software bug introduced by a code change, discovered by unit tests during the automated testing phase. That, or it could be caused by a configuration change, resulting in a missing HTTP header that broke the integration tests.
The Shape of Testing
Each step of the SDLC requires individual forms of testing. This includes:
- Unit tests for individual components/units of work
- Integration tests for vetting relations between components of a binary package or between the frontend and backend of an application
- Database tests to evaluate accuracy and reliability of database systems
- E2E tests to verify the whole system is built according to business requirements and user journeys, which reduces backtracking in the event an error has been identified
Build failure notifications and log processing speed directly depend on the specific CI/CD pipeline toolchain implemented in your development environment. Also important are the frameworks you have integrated and the quality of the error handling mechanism, which should be able to identify errors in single minutes. The particular testing layers are aimed at addressing an app’s functionality, performance and reliability. The Test Pyramid provides developers with a framework that can effectively guide processes and shape their testing.
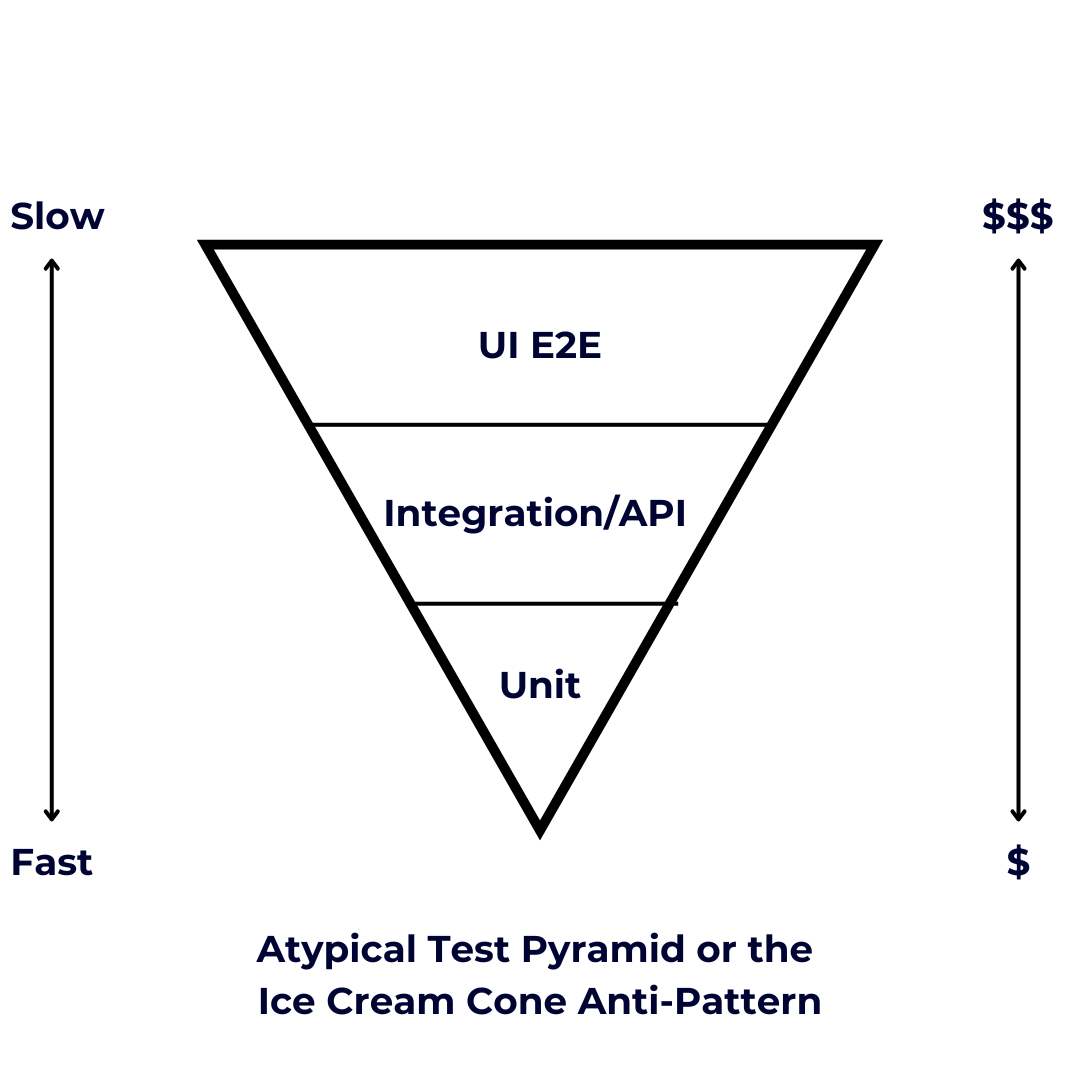
Unit tests focus on a single method or component. They’re quick, affordable and a good first-pass for ensuring code quality. They are written using the same language as the code they test, usually stored close by, and maintenance of these is the same as the application code, including all SDLC procedures. It’s important these tests are done in the build stage and prior to any code deployment to avoid unnecessary steps in case it is broken. If not, the tests will flag the build as a failure and prevent the next steps in the pipeline.
Next are the Integration and API tests. These are used to ensure the components and different layers of the application are working as expected and communication is happening between them using expected scenarios. In this type of test we can use different frameworks and languages: It’s not necessary to use the same language in which your application is written. It’s also important to understand that to run these you must be able to deploy the code first as many require usage of publicly available methods.
Then there are user interface (UI) E2E tests, the most encompassing of all, analyzing system integrations across the frontend, backend, databases and networking. These are usually created by QA who work with all lines of business and individual product owners. These tests are the costliest, consuming the most time and maintenance, particularly as business needs grow.
Traditional testing approaches often rely on the standard Test Pyramid (as seen above), which prioritizes unit tests at the base, followed by integration tests, with a small apex of E2E tests. However, an atypical or "inverted" Test Pyramid emerges when teams overemphasize E2E testing.
This antipattern creates a "leaking ice cream cone" architecture where:
- E2E tests dominate the testing strategy
- Lower-level tests become sparse
- Maintenance complexity escalates exponentially
- Resource consumption increases disproportionately
The result is a testing approach that's fragile against business requirement changes, computationally expensive, and strategically misaligned with efficient software development principles.
Testing apps manually isn’t easy and consumes a lot of time and money. Testing complex ones with frequent releases requires an enormous number of human hours when attempted manually. This will affect the release cycle, results will take longer to appear, and if shown to be a failure, you’ll need to conduct another round of testing. What’s more, the chances of doing it correctly, repeatedly and without any human error, are highly unlikely. Those factors have driven the development of automation throughout all phases of the testing process, ranging from infrastructure builds to actual testing of code and applications
As for who should write which tests, as a general rule of thumb, it’s a task best-suited to software engineers. They should create unit and integration tests as well as UI e2e tests. QA analysts should also be tasked with writing UI E2E tests scenarios together with individual product owners. QA teams collaborating with business owners enhance product quality by aligning testing scenarios with real-world user experiences and business objectives.
The test discovery phase, typically conducted manually, establishes the foundation for UI end-to-end tests, which are often implemented using Gherkin language. Gherkin, a structured syntax for behavior-driven development (BDD), follows a specific format:
- Given (initial context or preconditions)
- When (action or event occurs)
- Then (expected outcome or result)
This structure allows testers to define clear, readable scenarios that bridge the gap between business requirements and technical implementation. Gherkin's “Given-When-Then” format facilitates effective communication between stakeholders and developers, ensuring test cases accurately reflect desired behaviors and user stories gathered during the discovery phase. Many testing frameworks support this format, and it has proven very efficient and easily convertible into executable steps, making it a go-to tool for test design.
A Case for Testing
Testing can be carried out successfully with readily available tools and services. Amazon Web Services (AWS), one of the most widely used today, is a good case in point.
AWS CodePipeline can provide completely managed continuous delivery that creates pipelines, orchestrates and updates infrastructure and apps. It also works well with other crucial AWS DevOps services, while integrating with third-party action providers like Jenkins and Github. As a result, AWS CodePipeline can provide many vital capabilities and functionality, alongside scalability and cost efficiency. Here are advantages you can expect with AWS Codepipeline:
- Enables automated software release workflows
- Seamless connection with AWS and third-party services
- Easy configuration and real-time status tracking
- Adapts to complex deployment requirements
- Integrated with AWS Identity and Access Management (IAM)
- Pay only for actual pipeline actions executed
AWS CodePipeline offers a detection option that can kick off a pipeline centered on the source location of the artifacts. This is particularly useful for tasks such as function descriptions and risk assessments. When it comes to leveraging those stored artifacts, AWS encourages using Github webhooks along with Amazon CloudWatch Events. The tool also has a “disable transition” feature that connects pipeline stages and can be used as a default. To keep from automatically advancing, you simply need to hit a button and activities cease.
AWS CodePipeline allows pipeline edits for starting, updating or completely removing stages as well. An edit page lets users add actions as a series or alongside ongoing activities. This brings added flexibility to a pipeline and can better scale growth. When it comes to management, an approval action feature offers firm oversight of stages. For instance, if someone tasked with approval has not weighed in, the pipeline will close down until they do so.
Finally, AWS CodeBuild and CodePipeline work together seamlessly to create a powerful continuous integration and continuous delivery (CI/CD) pipeline. You can have multiple CodeBuild actions within a single CodePipeline stage or across different stages. This allows for parallel builds, different build environments or separate build and test actions.
The following is a brief example of the orchestration, using some demo code that stimulates the deployment of the application and includes the test phase. This is more like a pseudo code with guidelines rather than the completed solution, but it could be easily converted into a running pipeline with some changes and adaptations. For the simplicity of the example, I will use AWS ElasticBeanstalk as a service to host the application.
So let's describe the architecture of our solution:
- Source: GitHub repository (we are going to pull the application)
- Build: AWS CodeBuild (we are going to build and run the unit test)
- Uploading Artifacts (the artifacts would be stored on S3)
- Deploy: AWS Elastic Beanstalk (our hosting service on AWS)
- Testing: AWS CodeBuild for E2E tests (executing these tests against a newly deployed version of our application)
*I used a text-to-diagram tool called Eraser for this sketch. Very easy prompting and you can manually edit results.
Assuming we store our code in a version control system such as GitHub, the action (a code commit) on the code repository will trigger the source stage of the AWS CodePipeline, and the latest code will be pulled.
During the build phase, compile application code and execute unit tests to validate component functionality and ensure code quality. Then you can advance to the deploy stage with AWS Elastic Beanstalk as a deploy provider, after which you can move on to the testing stage and run the E2E test suite against the newly deployed version of the application. The testing stage involves approving the deployment and reports test results. In case of a failure, we then have to take care of the rollback, using the AWS ElasticBeanstalk configuration.
In order to manually provision a pipeline and the components you need to complete the orchestration, there are some steps you need to follow:
The Codepipeline setup:
- Inside your AWS console, type the Codepipeline and open the service
- Click "Create pipeline"
- Choose "Build custom pipeline" and click "Next"
- Add the name of your pipeline
- Select "V2" for pipeline type
- Choose the service role (new or existing)
- Click "Next"
Next is to configure the Source Stage:
- Select Github V2 as the source provider (assuming you use Github)
- Click "Connect to Github"
- Select repository and the branch
- Click "Next"
Now here’s the Build Stage:
- Use "AWS CodeBuild" as your build provider
- Select Region
- Click "Create project," name it and configure the build environment, add buildspec configuration file
- Add input artifact
- Add output artifact
- Click "Next"
Deploy Stage:
- Select "AWS Elastic Beanstalk" as your deploy provider
- Select Region
- Provide application name, environment name and artifact
- Enable automatic rollback under "Advanced"
- Click "Next"
E2E Tests Stage:
- Click "Add Stage"
- Add name
- Click "Add actions group"
- Add action name
- Select Action provider "AWS CodeBuild"
- Input artifact
- Select CodeBuildProject or create a new one
- Configure the test environment and buildspec
Now you should review and create your pipeline. In order to complete it, you would need to finish the build project in AW CodeBuild. To configure your Elastic Beanstalk environment, make sure you have all health checks and monitoring set up.
Next up are the configuration files for builds and AWS Codepipeline. Consider these as examples because your specific workload could use different frameworks and languages. This could make deployed strategies and destination services could vary.
Codepipeline-config.yaml:
{
"pipeline": {
"name": "web-app-pipeline",
"roleArn": "arn:aws:iam::account:role/service-role/pipeline-role",
"artifactStore": {
"type": "S3",
"location": "my-pipeline-artifact-bucket"
},
"stages": [
{
"name": "Source",
"actions": [
{
"name": "Source",
"actionTypeId": {
"category": "Source",
"owner": "AWS",
"provider": "CodeStarSourceConnection",
"version": "1"
},
"configuration": {
"ConnectionArn": "arn:aws:codestar-connections:region:account:connection/xxx",
"FullRepositoryId": "owner/repo",
"BranchName": "main"
},
"outputArtifacts": [
{
"name": "SourceCode"
}
]
}
]
},
{
"name": "Build",
"actions": [
{
"name": "BuildAndTest",
"actionTypeId": {
"category": "Build",
"owner": "AWS",
"provider": "CodeBuild",
"version": "1"
},
"configuration": {
"ProjectName": "web-app-build"
},
"inputArtifacts": [
{
"name": "SourceCode"
}
],
"outputArtifacts": [
{
"name": "BuildOutput"
}
]
}
]
},
{
"name": "Deploy",
"actions": [
{
"name": "Deploy",
"actionTypeId": {
"category": "Deploy",
"owner": "AWS",
"provider": "ElasticBeanstalk",
"version": "1"
},
"configuration": {
"ApplicationName": "web-application",
"EnvironmentName": "web-app-prod"
},
"inputArtifacts": [
{
"name": "BuildOutput"
}
],
"onFailure": {
"result": "ROLLBACK"
},
}
]
},
{
"name": "E2ETest",
"actions": [
{
"name": "E2ETests",
"actionTypeId": {
"category": "Test",
"owner": "AWS",
"provider": "CodeBuild",
"version": "1"
},
"configuration": {
"ProjectName": "web-app-e2e"
},
"inputArtifacts": [
{
"name": "SourceCode"
}
]
}
]
}
]
}
}
# buildspec.yml for main build
# a snippet of the phases for the build stage
# code versions and commands are for example only
version: 0.2
phases:
install:
runtime-versions:
nodejs: 18
pre_build:
commands:
- npm install
build:
commands:
- npm run build
- npm run test
post_build:
commands:
- echo Build completed
artifacts:
files:
- '**/*'
base-directory: 'dist'
# buildspec-e2e.yml for E2E tests
# a snippet for the e2e tests
# code versions and commands are for example only
version: 0.2
phases:
install:
runtime-versions:
nodejs: 18
pre_build:
commands:
- npm install
build:
commands:
- npm run e2e-tests
In addition, you have to create IAM service roles for CodeBuild and Codepipeline. These should look like the following:
Codepipeline service role policy example:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject*",
"s3:PutObject",
"s3:GetBucketVersioning"
],
"Resource": [
"arn:aws:s3:::my-pipeline-artifact-bucket/*",
"arn:aws:s3:::my-pipeline-artifact-bucket"
]
},
{
"Effect": "Allow",
"Action": "codestar-connections:UseConnection",
"Resource": "${ConnectionArn}"
},
{
"Effect": "Allow",
"Action": [
"codebuild:StartBuild",
"codebuild:BatchGetBuilds"
],
"Resource": "arn:aws:codebuild:${region}:${account}:project/web-app-*"
},
{
"Effect": "Allow",
"Action": [
"elasticbeanstalk:CreateApplicationVersion",
"elasticbeanstalk:DescribeApplicationVersions",
"elasticbeanstalk:DescribeEnvironments",
"elasticbeanstalk:UpdateEnvironment"
],
"Resource": "*"
}
]
}
Codebuild service role policy example:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:region:account:log-group:/aws/codebuild/*"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::my-pipeline-artifact-bucket/*"
]
},
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage"
],
"Resource": "*"
}
]
}By automating your release process, CodePipeline helps improve your team's productivity, increases the speed of delivery, and enhances the overall quality and reliability of your software releases.
This Isn’t Just a Test
The blowback that can come when an untested, buggy app makes its way into mainstream use can be severe. And there’s virtually no reason that should happen when proven technology for testing exists.
I think we all heard about the plane crash in Ethiopia in 2019, involving a Boeing 737 with people aboard. There was a lot of investigation and some findings pointed to a lack of testing and human factors. This included incomplete testing protocols, insufficient simulation testing, and poorly implemented safety measures and risk mitigation testing.
The lack of a proper or comprehensive specification was the factor that led to these incomplete procedures. As a result, lives were lost. Today, in most cases, the failure of implementing proper specs and comprehensive testing will not end up in a tragedy like this, but it will impact the business and potentially cause lots of unwanted expenses or losses.
Just focus attention on tools that automate functions and take human error out of the equation. Equally important, be sure everyone involved in development has a role in testing, whether they’re coders, engineers or in QA. Shared responsibility across your organization ensures everyone has a stake in its success. The goal should be to deliver business value and your tools should support this.
After all, this isn’t just a test, it isn’t just the toolset, it’s the way to drive DevOps for business success.
Opinions expressed by DZone contributors are their own.
Comments